

這次介紹如何使用TensorFlow解決Classification(分類)問題。在學習Classification時,會使用到MNIST 資料庫,裡面包含有手寫數字視覺資料集如圖1:
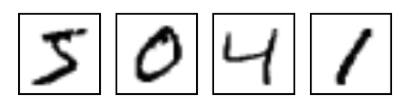
圖1 MNIST數字集
它也包含每一張圖片對應的標籤,告訴我們這個是數字幾。比如,圖1這四個數字的標籤分別是5,0,4,1。我們使用的是 TensorFlow 官方提供的 MNIST 資料集,MNIST 資料集中的影像是 28 x 28 = 784 的手寫數字影像,如果將其中一張影像的像素 (pixels) 以矩陣的方式呈現,可以看到那些數值所呈現的形狀即是手寫數字的形狀,所以我們將利用這些數值來預測手寫數字。
MNIST資料庫:
從 TensorFlow 的資料集中引入 MNIST,同時對影像的 labels 做 One-hot encoding。每一個MNIST數據單元有兩部分組成:一張包含手寫數字的圖片和一個對應的標籤。我們把這些圖片設為“x”,把這些標籤設為“y_”。訓練數據集和測試數據集都包含x和y_,比如訓練數據集的圖片是 mnist.train.images ,訓練數據集的標籤是 mnist.train.labels。
第一次讀取 MNIST 的資料集時,會自動將資料下載至 ./MNIST_data 中,下次讀取時,程式會直接從已經下載的資料中讀取。

圖2 讀取MNIST資料庫
什麼是 One-hot encoding?
One-hot encoding 是將類別以 (0, 1) 的方式表示,舉例來說,假設有 cat、dog、bird 三個類別,而三個類別可以用 (1, 0, 0)、(0, 1, 0)、(0, 0, 1) 來表示。
之所以用 One-hot encoding 的原因是,一般來說,我們在做 Classification 時,其資料的 label 是用文字代表一個類別,例如做動物的影像辨識,label 可能會是 cat、dog、bird 等,但是類神經網路皆是輸出數值,所以我們無法判斷 34 與 cat 的差別。因此,One-hot encoding 便是在做 Classification 經常使用的一個技巧。
定義類神經網路模型:
MNIST 的影像是 28(width)×28(height)=784 (pixels),所以我們定義輸入層 x 為 784 個節點;而 0~9 有 10 個類別,則定義輸出層 y_ 為 10 個節點。因為 Softmax 回歸是一個單層的類神經網路模型,所以我們只要定義一個 W 跟 b,以及類神經網路運算的流程 y。

圖3定義神經網路
損失函數(Loss Function)
在 Softmax 回歸這個例子,所使用的損失函數是交叉熵(Cross Entropy) 。交叉熵是評估兩個機率分配(distribution) 有多接近,如果兩著很接近,則交叉熵的結果趨近於 0;反之,如果兩個機率分配差距較大,則交叉熵的結果趨近於 1。而訓練模型的目的是讓損失函數 —— cross entropy 的數值最小化,亦即使得輸出預測的機率愈接近真實機率。TensorFlow 提供了結合 Softmax 與 Cross Entropy 的函式,讓我們可以一次做到這兩件事,而且 softmax_cross_entropy_with_logits 提供更穩定的數值。

圖4 損失函數
優化器(Optimizer):
選擇的優化器是常見的梯度下降。

圖5 優化器
練神經網路
在訓練類神經網路之前,我們先定義計算準確度的運算。首先,判斷預測值與真實值是否一樣,correct_prediction 是一個 [True, False] 的陣列,再經由計算平均 (True=1,False=0),就可以得到準確度 accuracy。

圖6 訓練神經網路
最後,啟動 Session 與計算圖溝通,開始訓練類神經網路的模型。在這個範例中,每次都會將 100 筆的手寫影像送進 placeholder 中。
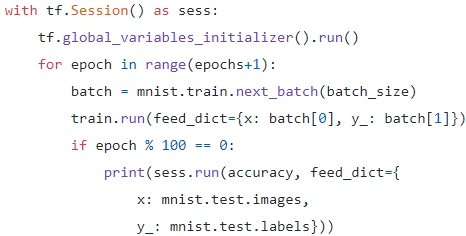
圖7 神經網路運算

圖8 精確度
Softmax 回歸是一個多分類的類神經網路結構,我們可以使用它快速建立一個手寫辨識的模型,準確率最高可以達到 0.919。

評論