

在上一篇提到利用機器學習辨識手寫文字,在訓練時得到的訓練誤差很低,但是訓練完的模型辨識文字的效果卻不好,這是什麼原因呢?這就是這張要說明的主題,擬合過度(Overfitting)。
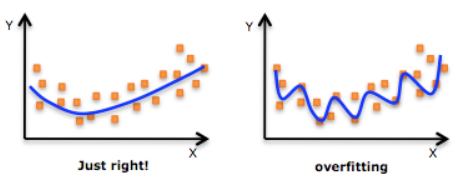
圖1 擬合過度(OverFitting)
機器學習模型的自負又表現在哪些方面呢?這裡是一些數據。如果要你畫一條線來描述這些數據,大多數人都會這麼畫,這條線也是我們希望機器也能學出來的一條用來總結這些數據的線圖1 (Just right)。這時藍線與數據的總誤差可能是10。可是有時候,機器過於糾結這誤差值,他想把誤差減到更小,來完成他對這一批數據的學習使命。所以,他學到的可能會變成這樣。它幾乎經過了每一個數據點圖1(overfitting),這樣誤差值會更小,可是誤差越小就真的好嗎? 看來我們的模型還是太理想化了。當我拿這個模型運用在現實中的時候,他的理想化就表現出來。我們還一堆現實數據。這時,之前誤差大的圖1 Just right誤差基本保持不變。誤差小的overfitting誤差值突然飆高,理想化的圖1 overfitting再也驕傲不起來,因為他不能成功的表達除了訓練數據以外的其他數據,這就叫做擬合過度(Overfitting)。
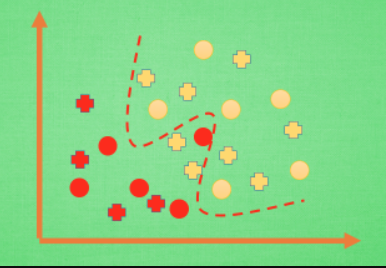
圖2 Overfitting
那麼在分類問題當中,擬合過度的分割線可能是這樣,再上一些真實數據。我們明顯看出,有兩個黃色的數據並沒有被很好的分隔開來。這也是擬合過度在作怪。好了, 既然我們時不時會遇到擬合過度的問題,那解決的方法有那些呢?
方法一:「搜集更多資料」。資料不均或資料過少都有可能讓模型對於那些未知的數據分佈無法掌握,資料的收集可以降低 Overfitting 的風險。在資料分析任務中,更多的數據往往能提高模型的準確性,且減少過度擬合的可能性。

圖3 正規化
方法二:運用正規化。L1、L2 regularization等等,這些方法適用於大多數的機器學習,包括神經網絡。他們的做法大同小異,我們簡化機器學習的關鍵公式為y=Wx。 W為機器需要學習到的各種參數。在過擬合中,W的值往往變化得特別大或特別小。為了不讓W變化太大,我們在計算誤差上做些手腳。原始的cost 誤差是這樣計算,cost = 預測值-真實值的平方。如果W 變得太大,我們就讓cost也跟著變大,變成一種懲罰機制。所以我們把W自己考慮進來。這裡abs 是絕對值。這一種形式的正規化,叫做l1 正規化,L2 正規化和l1 類似,只是絕對值換成了平方。其他的l3、l4 也都是換成了立方和4次方等等。形式類似,用這些方法,我們就能保證讓學出來的線條不會過於扭曲。
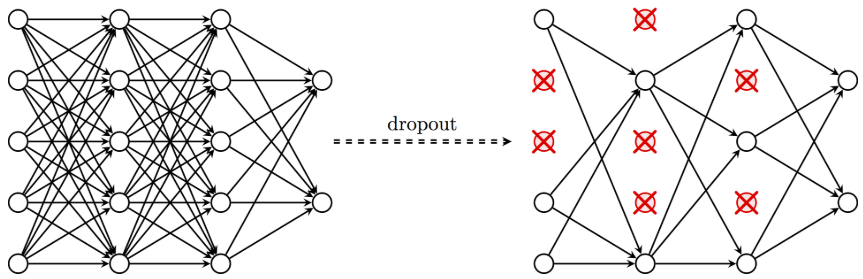
圖4 dropout
還有一種專門用在神經網絡的正規化的方法,叫作dropout。在訓練的時候,我們隨機忽略掉一些神經元和神經聯結,是這個神經網絡變得”不完整”。用一個不完整的神經網絡訓練一次,到第二次再隨機忽略另一些,變成另一個不完整的神經網絡。有了這些隨機drop 掉的規則,我們可以想像其實每次訓練的時候,我們都讓每一次預測結果都不會依賴於其中某部分特定的神經元。 像l1、l2正規化一樣,過度依賴的W , 也就是訓練參數的數值會很大,l1、l2會懲罰這些大的參數。Dropout 的做法是從根本上讓神經網絡沒機會過度依賴。

評論