

本文主要介紹以 NXP LPC55S69 平台開發的 E-Lock 方案OLED 顯示屏中文字庫建置流程說明;
- 顯示屏所使用的 OLED 控制 IC ( SH11106) 模組
- 說明 OLED 繁體中文資料庫及選單的建立
- 繁體中文語句字庫建表
各項細節會在後續文章進行說明。
2. OLED 模組簡介
OLED 模組 IC
本方案的 OLED 模組為1.3 吋,採用 SH1106 IC OLED 控制 IC,白字黑底,I2C 通信接口,兼容3.3V和5V。
OLED 液晶顯示面板為自發光,無需背光,省電節能
- 分辨率 :128 x 64 個點矩陣
- 寬電壓支持 :無需任何修改,直接支持 3.3~5V 直流
- 模組尺寸(長寬厚) :29.42×14.7(mm)
- 接口定義 :採用 IIC 通信方式,接口順序是 VCC,GND,SCL,SDA:
- 驅動芯片 :SH1106 控制器
- 模組不需字庫記憶體 :字庫預存放在 MCU 的 Flash memory 中,可顯示漢字、ASCII 、圖案等。

3. OLED 繁體中文字建模方式說明
3_1. OLED 的字元點陣
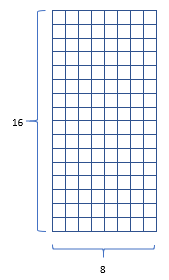
本方案的 OLED 模組的分辨率是 128 x 64 個點;我們將每個字元 (如大小寫英文字母 A ~ Z / a ~z,及標點符號等 ) 的大小定為 8 x 16 個點矩陣,如下圖所示:
3_2. OLED 的中文字點陣
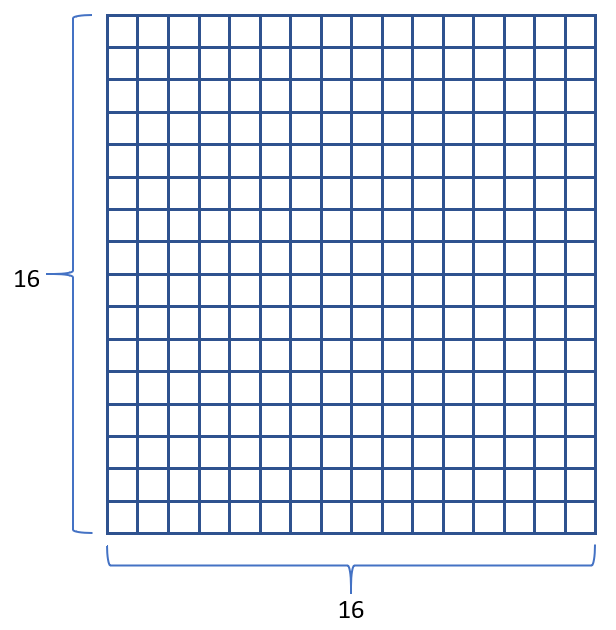
中文字的大小規劃為寬度是16 個點,高度是 16 個點;因此一個中文字是 16 x 16 = 256 個點矩陣。
3_3. 中文字點陣的處理方式
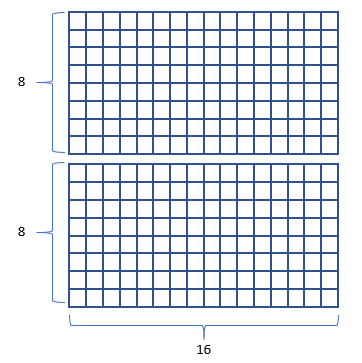
將這個 256 個點的中文字矩陣分拆成上下兩塊,可得到如右下圖兩塊 (2列) 8 x 16 的點矩陣:
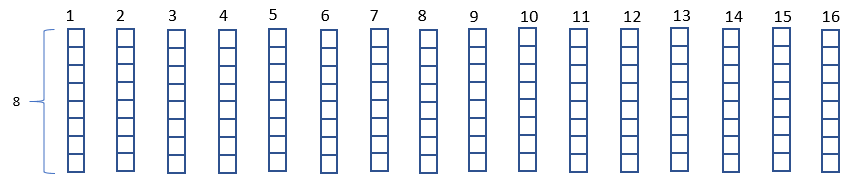
再將上或下的 8 x 16 個點陣分拆16 行,可得 16 行 8 個點組成的縱向點陣:
每一行的 8 個點可用1個 byte = 8 bit 表示,即每個 byte 中為 ‘1’ 的 bit 位置代表在該行中打點的位置;
比如 0x01 / 0x02 / 0x04 / 0x08 / 0x10 / 0x20 / 0x40 / 0x80 在該行中打點的位置如下圖所示:
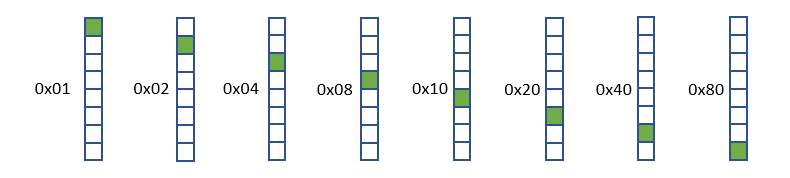
一行的數值用一個 byte 表示,如此,用 32 個 bytes 就可以描繪出一個完整的中文字。
網路上有現成的網站可以進行 OLED 中文字碼的轉換:
https://www.23bei.com/tool-218.html
該網頁進入後的畫面如下: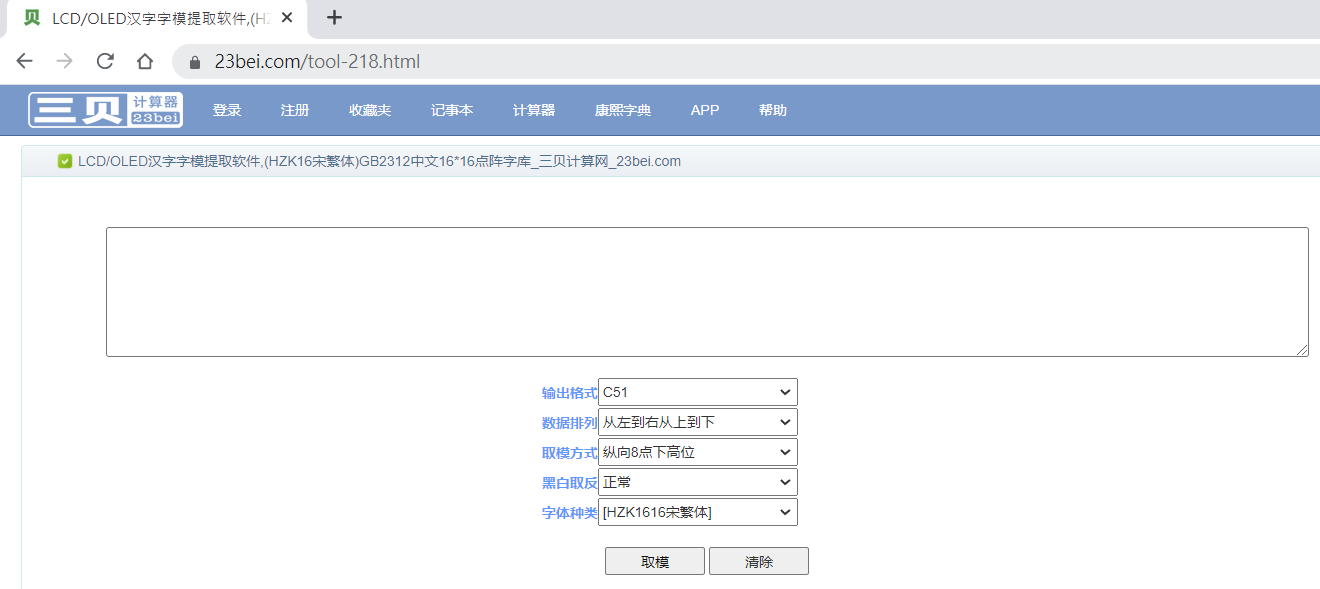
在轉換的選項部分,維持原先網頁的設定 (如下所示) 即可:
轉碼的方式很簡單,在文字輸入框中寫入欲轉換的中文字之後 (比如“中文” 兩字),
再按下 “取模” 的按鍵之後,即可產生轉碼之後的點陣代碼內容。
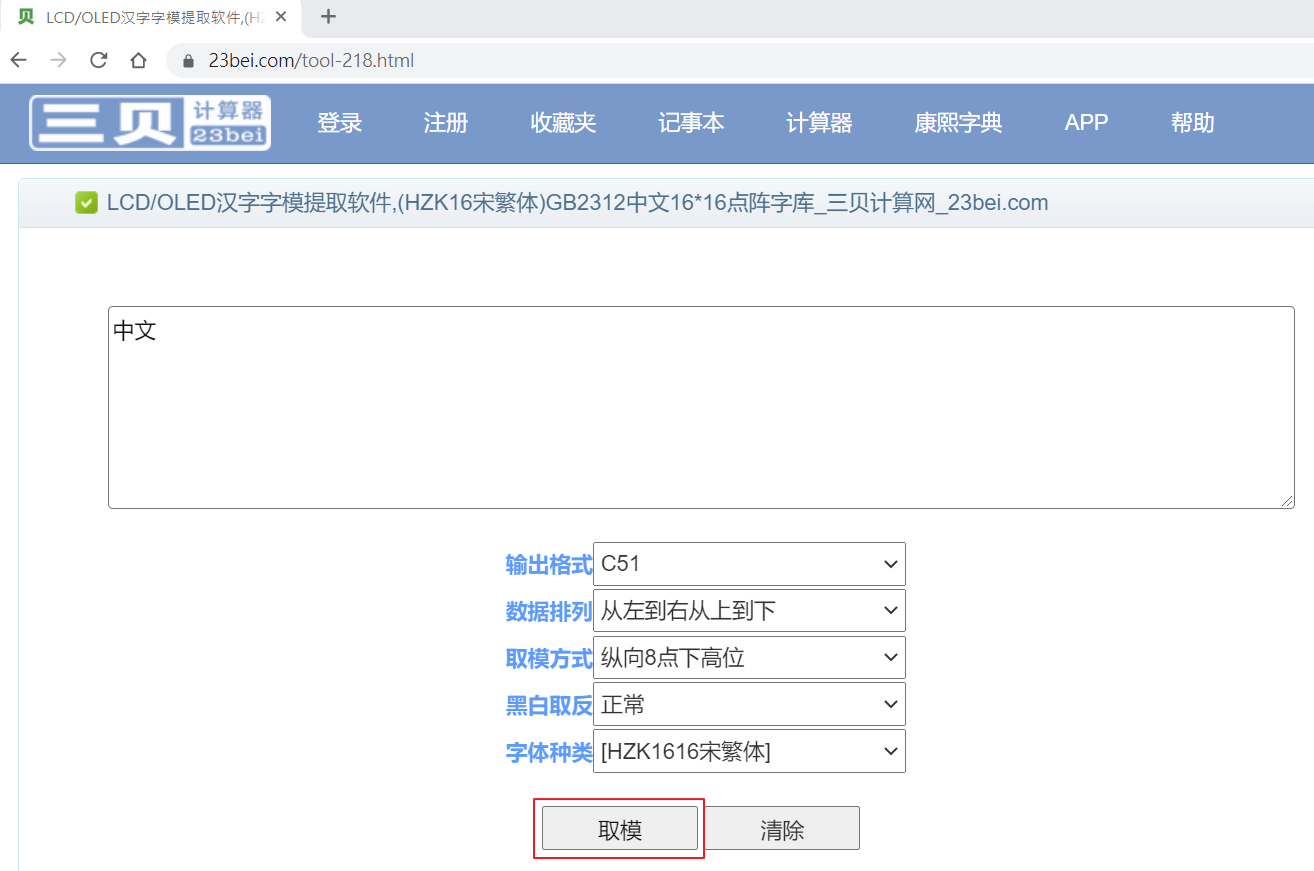
以下是轉碼後所生成的點陣代碼內容:
/* [字库]:[HZK1616宋繁体] [数据排列]:从左到右从上到下 [取模方式]:纵向8点下高位 [正负反色]:否 [去掉重复后]共2个字符[总字符库]:"中文"*/
/*-- ID:0,字符:"中",ASCII编码:D6D0,对应字:宽x高=16x16,画布:宽W=16 高H=16,共32字节*/
0x00,0xF8,0x08,0x08,0x08,0x08,0x08,0xFF,0x08,0x08,0x08,0x08,0x08,0xFC,0x08,0x00,
0x00,0x03,0x01,0x01,0x01,0x01,0x01,0xFF,0x01,0x01,0x01,0x01,0x01,0x03,0x00,0x00,
/*-- ID:1,字符:"文",ASCII编码:CEC4,对应字:宽x高=16x16,画布:宽W=16 高H=16,共32字节*/
0x08,0x08,0x08,0x18,0x68,0x88,0x09,0x0E,0x08,0x08,0xC8,0x38,0x08,0x0C,0x08,0x00,
0x80,0x80,0x40,0x40,0x20,0x11,0x0A,0x04,0x0A,0x11,0x10,0x20,0x40,0xC0,0x40,0x00
由上面的點陣代碼結果可以發現,每個字都是由兩列、每列16 個 bytes 的代碼所組成,一個字總共 32 bytes;
每一個中文字碼的第一列負責該字的上半部點字,第二列負責該字的下半部點字;
將上下兩列點陣字碼組合起來,即可如下圖一樣,描繪出中文字型中的每一的點。
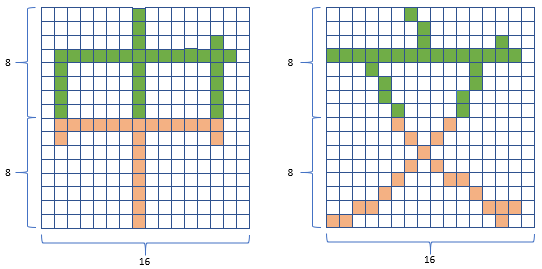
4. OLED 中文語句字庫建表
4_1. 建立中文字庫
我們將 OLED 選單中所要用到的中文字庫全部用上述所提到的網站建立出來,並將所轉換出來的轉碼置放入 f16x16[ ][32] 的二維陣列中
|
const unsigned char f16x16[][32] = { //-- ID:0,字符: " ", 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,
//-- ID:1,字符:"歡",ASCII编码:BBB6; ch_ 0x00,0x3A,0xAA,0x7F,0x02,0x42,0xBF,0x2A,0x3A,0x80,0x70,0x9F,0x10,0x50,0x30,0x00, 0x02,0x01,0xFF,0x55,0x55,0x7F,0x55,0x55,0xC1,0x40,0x38,0x07,0x18,0x60,0x80,0x00,
//-- ID:2,字符:"迎",ASCII编码:D3AD 0x40,0x42,0x44,0xC8,0x00,0xFC,0x04,0x02,0x82,0xFC,0x04,0x04,0x04,0xFE,0x04,0x00, 0x00,0x40,0x20,0x1F,0x20,0x47,0x42,0x41,0x40,0x7F,0x40,0x42,0x44,0x43,0x40,0x00,
: : :
//-- ID:196,字符:"體",ASCII编码:CCE5 0xC0,0x7E,0x4A,0x7A,0x42,0x7E,0xC0,0x7C,0x54,0x7F,0x54,0x7F,0x54,0x7C,0x00,0x00, 0x00,0xFF,0x15,0x55,0x95,0x7F,0x80,0x9D,0xB5,0xD5,0x95,0xD5,0xB5,0x9D,0x80,0x00,
//-- ID:197,字符: " ", 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,
}; |
我們用 f16x16[ROW][COLUMN] 的 ROW 及 COLUMN 來代表這個二維陣列的兩個維度
f16x16[ ][32] : [32] 表示在[COLUMN] 這個維度中,每一個 font 都是由 32 個 bytes 所組成
f16x16[ ][32] : [ ] 則表示在 [ROW] 這個維度中,所要填入的數字意謂要取用 f16x16[ ][32] 這個陣列所存放的第幾個中文字;
這個值也就是應對該字庫每個字的‘index’, 這個 index 數值直接指向要取用該字庫的第幾個中文字。
4_2. 字庫所使用的 index
使用直接數值 (如 1, 2, 3, … 等) 代入這個二維陣列 f16x16[ ][32] 的 index來取用其中的 font,
在字庫存放字數多時,並不容易用來區別是要取用哪一個字;
所以我們將字庫中每個字以羅馬拼音命名並使用列舉的方式處理編號,做為簡單的識別;
以此列舉識別名稱代替直接數值做為 index,在使用時會便於簡單的識別:
|
enum ch_lib { ch_space0 = 0, // " " ch_huan1 = 1, // 歡 ch_ying2 = 2, // 迎 ch_huei3 = 3, // 回 ch_lai4 = 4, // 來 ch_miao5 = 5, // 秒 ch_yong6 = 6, // 用 ch_chi7 = 7, // 其 ch_ta8 = 8, // 他 ch_qing9 = 9, // 請 ch_shu10 = 10, ch_ru11 = 11, ch_mi12 = 12, ch_ma13 = 13, ch_yi14 = 14, ch_zhong15 = 15, ch_hao16 = 16, ch_jian17 = 17, ch_jie18 = 18, : : : ch_siao195 = 195, // 消 ch_ti196 = 196, // 體 ch_space197 = 197, // "space" }; |
4_3. OLED 語句字庫的建表
語句是由每一個文字所組成,所以建好文字字庫之後,還需要建立語句以方便該語句的提取,便於在 OLED 顯示語句時使用。
以下就是依照上一節所建的字庫的列舉 index 值,分別用各個語句建立 OLED 的語句陣列:
|
const char ch_hyhl[5] = {ch_huan1, ch_ying2, ch_huei3, ch_lai4}; // 0. 歡迎回來 const char ch_mmgly[6] = {ch_mi12, ch_ma13, ch_guan30, ch_li31, ch_yuan32}; // 1.密碼管理員 const char ch_mmyh[5] = {ch_mi12, ch_ma13, ch_yong6, ch_hu45}; // 2.密碼用戶 const char ch_kpyh[5] = {ch_ka54, ch_pian55, ch_yong6, ch_hu45}; // 3.卡片用戶 const char ch_zwgly[6] = {ch_zhi42, ch_wen43, ch_guan30, ch_li31, ch_yuan32}; // 4.指紋管理員 const char ch_zwyh[5] = {ch_zhi42, ch_wen43, ch_yong6, ch_hu45}; // 5.指紋用戶 const char ch_rlgly[6] = {ch_ren68, ch_lian69, ch_guan30, ch_li31, ch_yuan32}; // 6.人臉管理員 const char ch_rlyh[5] = {ch_ren68, ch_lian69, ch_yong6, ch_hu45}; // 7.人臉用戶 const char ch_yzsb[5] = {ch_yan28, ch_zheng29, ch_shi37, ch_bai38}; // 8.驗證失敗 : : : const char ch_yhzw[5] = {ch_yong6, ch_hu45, ch_zhi42, ch_wen43}; // 69.用戶指紋 const char ch_glyrl[6] = {ch_guan30, ch_li31, ch_yuan32, ch_ren68, ch_lian69}; // 70.管理員人臉 const char ch_yhrl[5] = {ch_yong6, ch_hu45, ch_ren68, ch_lian69}; // 71. 用戶人臉 |
4_4. 調用 API 提取 OLED 句庫中的語句
當要顯示某中文語句時,調用以下的 API
|
void OLED_ShowCH(uint8_t x_pos, uint8_t y_pos, const char ch[]) |
其中,x_pos 及 y_pos 的引數表示該語句要從 OLED 的哪一列的第幾個位置開始顯示,
ch[ ] 這個引數的位置則代入要顯示的語句的陣列名稱即可。
以下這句 “主選單” 做為範例,
主選單語句陣列宣告如下:
|
const char ch_zcd[4] = {ch_zhu39, ch_xuan152, ch_dan41}; // 14. 主選單 |
調用 OLED_ShowCH( ) 這個 API:
|
OLED_ShowCH(40, 0, ch_zcd); |
x_pos 代入 40,y_pos 代入 0,在 ch[ ] 這個引數位置代入“主選單”這個陣列名稱 “ch_zcd”,
就會從 OLED 第 0 行,第 40 個點的位置開始顯示 “主選單” 這三個字。
4_5. 使用列舉方式方便提取 OLED 句庫中的語句
我們將所有的語句 “陣列名稱” 使用如下的陣列名稱 *ch_ptrArray 收錄起來:
|
const char *ch_ptrArray[] = { ch_hyhl, // 0 歡迎回來 ch_mmgly, // 1 密碼管理員 ch_mmyh, // 2 密碼用戶 ch_kpyh, // 3 卡片用戶 ch_zwgly, // 4 指紋管理員 ch_zwyh, // 5 指紋用戶 : : : ch_yhzw, // 69 用戶指紋 ch_glyrl, // 70 管理員人臉 ch_yhrl, // 71 用戶人臉 }; |
就可以下面的方式呼叫 OLED_ShowCH(uint8_t x_pos, uint8_t y_pos, const char ch[]) API:
ch_ptrArray[ n ] 中的 ‘n’ 值,則填入上述陣列中要取用的語句的次序值即可。
如此,只要使用查表的方式,就可以比較輕鬆的使用中文語句。
|
OLED_ShowCH(40, 0, ch_ptrArray[n]); |
由於篇幅的關係,和 OLED 有關的其他 API 介紹就不在此篇博文介紹。
5. 參考資料
OLED driver IC datasheet :
https://www.velleman.eu/downloads/29/infosheets/sh1106_datasheet.pdf
- NXP 官網: https://www.nxp.com/
- NXP LPC55S69 Doc ( Datasheet、User manual )
- 建立繁體中文字庫的網站: https://www.23bei.com/tool-218.html