

一. 概述
本文主要將介紹恩智浦近期所推廣的 AI 晶片 : 神經處理單元( Neural Process Unit, NPU )。
此篇主要探討 NPU 的進階使用介紹,像是如何利用 NPU 的進行推理,如何加快暖開機時間,如何顯示 NPU 推理時的細節資訊,亦或是如何選用 NPU 或 GPU 進行推理。
如下圖文章架構圖所示,此架構圖隸屬於 i.MX8M Plus 的方案博文中,並屬於機器學習內的 硬體層(Hardware Layer) 的 NPU 部分,目前章節介紹 “NPU 實際操作”。此外,方塊圖的右側也展示了一些小圖示,加註說明其中的對應關係。比如說應用層就會對應上 eIQ 的使用。推理引擎層則是各式各樣的推理引擎,如 TensorFlow Lite 、 ONNX Runtime 、 ArmNN 等等,硬體加速層則由 OpenVX 以最佳的方式來驅動硬體。
若新讀者欲理解更多人工智慧、機器學習以及深度學習的資訊,可點選查閱下方博文
大大通精彩博文 【ATU Book-i.MX8系列】博文索引
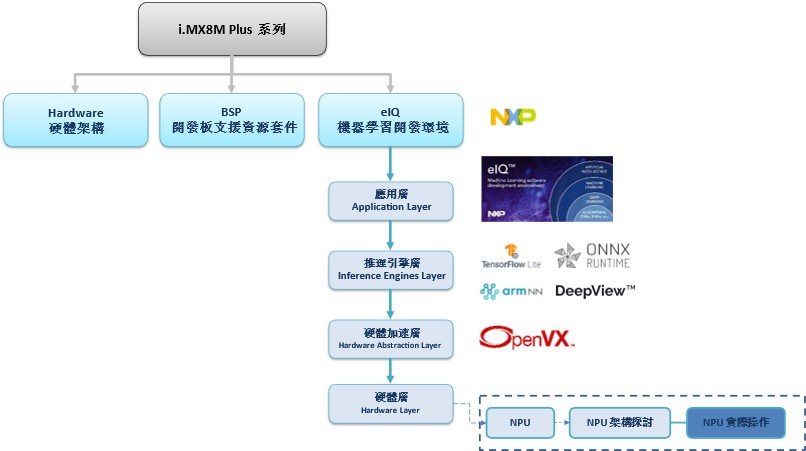
NPU 系列博文-文章架構示意圖
二. NPU 實際操作
首先會向讀者介紹 NPU 的實際操作概念,也就是如何利用推理引擎來完成機器學習的應用 ,以及如何查看 NPU 相關執行資訊。 最後說明何謂 NPU 的暖開機,並如何減少暖開機所花費時間 !! 以及一些關於 NPU 環境變數的設定 !!
操作概念 :
對於恩智浦的 NPU 的使用方式,就如 eIQ 系列所述,大致上就是從 推理引擎(inference engine) 的層級來選擇 CPU 、 GPU 或是 NPU 進行推理(Inference),也就是最常見的應用端的做法。
如同下方架構圖所示,從 TensorFlow Lite 推理引擎來觀察,可以發現將以 XNNPACK Delegate (專門用於 Arm 加速)、NNAPI Delegate(專門用於 GPU/NPU 加速) 、VX Delegate(專門用於 GPU/NPU 加速) 等委託服務來進行推理 !!再進一步探討下去,就能發現其來源是由 OVXLib 與 OpenVX Driver 進行動作,也就是引用 OpenVX 的動態連結庫,也就用到硬體加速層,利用此庫的優化來達到硬體加速最佳化之目的。 而 NXP 提供完善的 API 應用,讓讀者或是軟體工程師僅須要選擇哪種 Delegate ,就能達到不同硬體加速的使用體驗。
PS : 其中 ArmN、ONNX、DeepViewRT 等推理引擎的操作概念相近
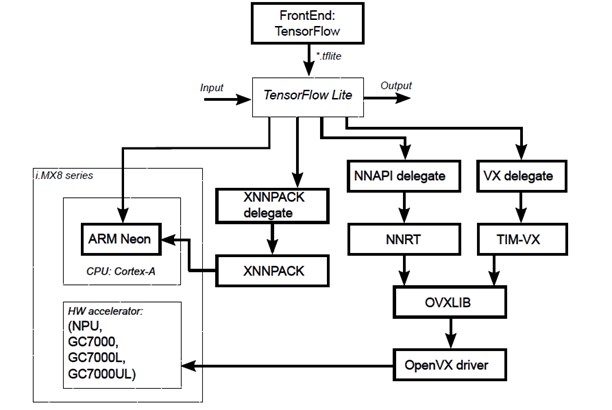
TensorFlow Lite 推理方式示意圖
資料來源 : 官方網站
操作方式 ( C/C++ ) :
此範例使用 TensorFlow Lite 框架結合輕量化網路模型 MobileNet 去分類物件,並提供不同的後端推理方式給予讀者作參考。
(1) 開啟終端機,進入範例之所在位置 (開發板系統內)
cd /usr/bin/tensorflow-lite-2.6.0/examples(2) 後端推理方式
- 範例之運行 ARM NEON 後端推理方式
./label_image -m mobilenet_v1_1.0_224_quant.tflite -i grace_hopper.bmp -l labels.txt - 範例之運行 XNNPACK delegate 後端推理方式
./label_image -m mobilenet_v1_1.0_224_quant.tflite -i grace_hopper.bmp -l labels.txt --use_xnnpack=true- 範例之運行 NNAPI delegate 後端推理方式
./label_image -m mobilenet_v1_1.0_224_quant.tflite -i grace_hopper.bmp -l labels.txt -a 1- 範例之運行 VX delegate 後端推理方式
./label_image -m mobilenet_v1_1.0_224_quant.tflite -i grace_hopper.bmp -l labels.txt --external_delegate_path=/usr/lib/libvx_delegate.so
(3) 運行結果
在 i.MX8M Plus 實測結果依序為 軍服(military uniform) 76.4 % 、溫莎領帶(Windsor tie) 12.1 % 、 領結(bow tie) 1.56 %,故此圖片最相似於 軍服(military uniform) 的特徵分類。其中所花費的推理時間為 ARM NENO 約 44.59 ms 、XNNPACK delegate 約 43.46 ms 、NNAPI delegate (NPU) 約 2.767 ms 、VX delegate (NPU) 約 2.576 ms 。
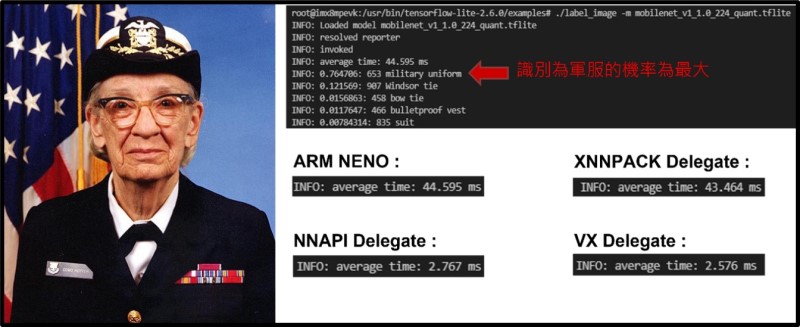
*** BSP 5.10.35 運行結果 ***
操作方式 ( Python ) :
此範例使用 TensorFlow lite 框架結合輕量化網路模型 MobileNet去分類物件,但與 C/C++ 的差異是 Python 對於底層的支援性較差一些。
在最新的 BSP 版本中,僅提供 XNNPACK 與 VX Delegate 。
(1) 開啟終端機輸入
python3(2) 後端推理方式
- 範例之運行 XNNPACK delegate 後端推理方式
#以 TensorFlow Lite 進行推理 (此處為部分代碼)
interpreter = tflite.Interpreter(model)- 範例之運行 NNAPI delegate 後端推理方式
#(於 BSP L5.10.52 後取消此 Delegate)- 範例之運行 VX delegate 後端推理方式
#以 TensorFlow Lite 進行推理 (此處為部分代碼)
ext_delegate = [ tflite.load_delegate("/usr/lib/libvx_delegate.so") ]
interpreter = tflite.Interpreter(model, experimental_delegates=ext_delegate)PS : 若欲查看整段 python 代碼,請點選此處
(3) 運行結果
如下圖所示,在 i.MX8M Plus 實測成功識別出 史奇派克犬(schipperke) 則機率為 76 %。
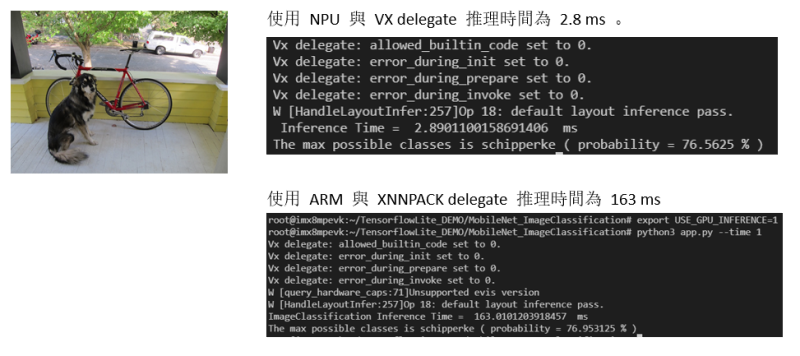
*** BSP 5.10.52 運行結果,其中 XNNPACK 數據有差距,由底層描述變更所導致 ***
NPU 資訊顯示方式 :
原廠提供一種方式能夠顯示 NPU 所計算的架構層、權重等訊息,啟用步驟如下 :
第一步 : 進入 Uboot
請重新開機,在啟動時按下 Enter 進入 Uboot 環境中。
第二步 : 設置環境變數,並離開 Uboot
$ editenv mmcargs $ galcore.showArgs=1 galcore.gpuProfiler=1
$ boot
第三步 : 重新啟動後,回到 i.MX8M Plus 之 Linux OS 系統下設置環境變數
$ export CNN_PERF=1 NN_EXT_SHOW_PERF=1 VIV_VX_DEBUG_LEVEL=1 VIV_VX_PROFILE=1第四步 : 進行推理,並產出記錄檔
範例 - C / C++ 推理演示 :
$ cd /usr/bin/tensorflow-lite-2.6.0/examples
$ ./label_image -m mobilenet_v1_1.0_224_quant.tflite -t 1 -i grace_hopper.bmp -l labels.txt -a 1 -v 0 > viv_test_app_profile.log 2>&1範例 - Python 推理演示 :
$ pyeiq --run object_classification_tflite > viv_test_app_profile.log
推理資訊 : 其 NPU 資訊將記錄於 viv_test_app_profile.log 中
如下,可以看出 NPU 神經網路的架構方式以及每個網路層的詳細資訊…
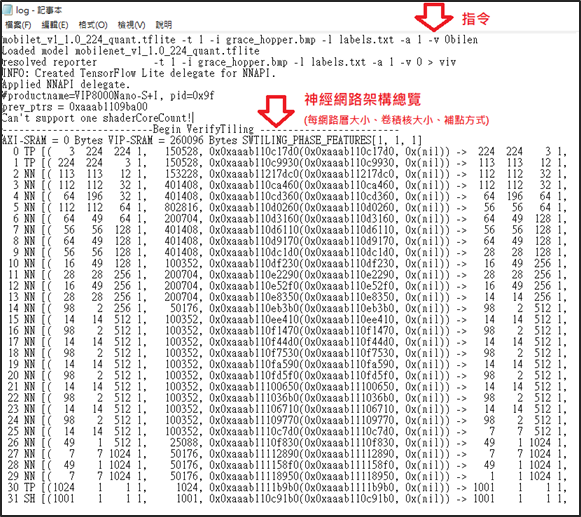
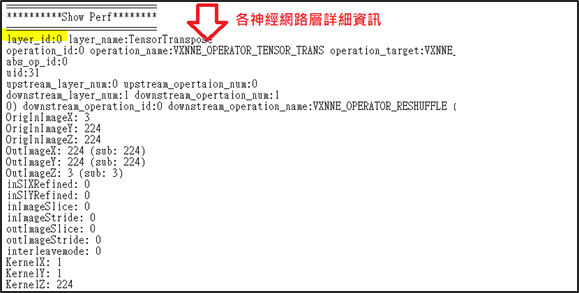
暖開機(Warm-up Time) :
暖開機(Warm-Up Time) 就如同 “NPU 架構探討” 所提即到一樣。在剛啟用 NPU 運算時,將會耗費大量的時間進行事前的推理規劃。這就類似在建立神經網路中的神經元,當有電流訊號去刺激神經元時,細胞就將開始被激活與產生相應的活動。故這裡將探討如何加快 NPU 暖開機的啟用時間。
在進行 NPU 的推理時,將會進行初始化、暖開機、推理演算動作。然而對於首次啟動而言,暖開機的時間遠遠大於推理的時間,就如同下表所示。在推理 MobileNet V1 模組時,暖開機時間約花費 7896 ms,而實際推理時間僅需 3.36 ms !!
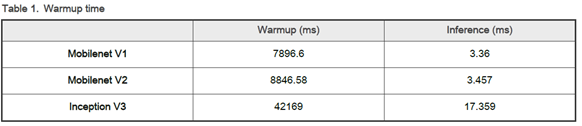
資料來源 : 官方網站
因此,暖開機所花費的時間是相當耗費的 ! 這裡提供一種改善方式,能使暖開機所花費的時間大幅度減少。此方式就是將所建立過的神經網路關係紀錄至檔案(.nb) 中,當再次啟用此推理時就僅以讀檔的方式即可完成推理,這種方式就稱作 Graph Catching !! 如同下表所示,在推理 MobileNet V1 模組時,沒有進行 Graph Catching 的方式須耗費 7896 ms。反之,有進行 Graph Catching 的方式僅須耗費 2192 ms !! 數據顯示,能大幅度減少暖開機時間 !!
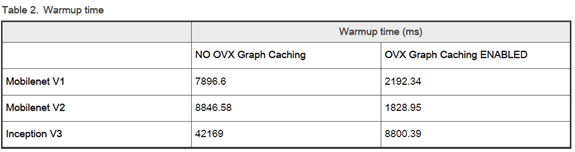
資料來源 : 官方網站
Graph Catching使用方式 :
在 i.MX8M Plus 之 Linux OS 環境中,輸入以下指令…
$ export VIVANTE_VX_CACHE_GRAPH_BINARY_DIR=`pwd`
$ export VIV_VX_ENABLE_CACHE_GRAPH_BINARY=”1”在首次執行 NPU 推理後,即可產生 .nb 檔案
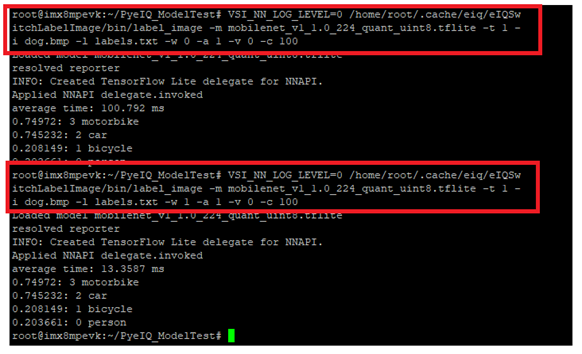
Graph Catching 使用展示 :
如下圖所示,第一次整個推理時間花費 100.792 ms ,第二次整個推理時間花費約 13 .35 ms 。以達到速度上的改善 !!
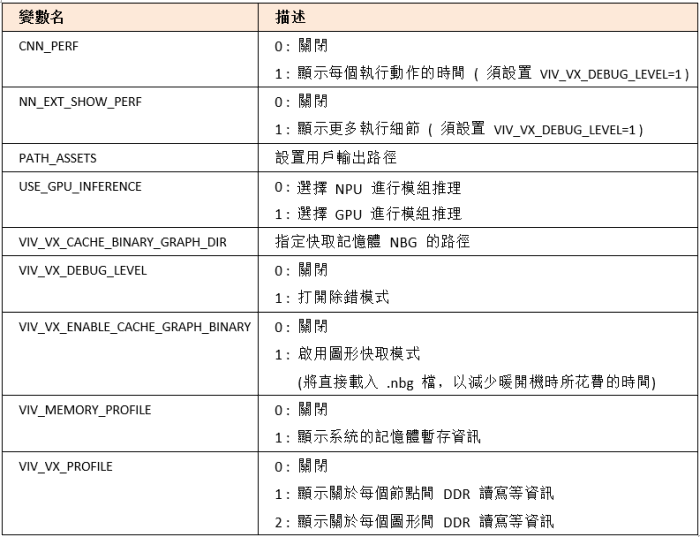
系統環境調整 :
最後,提供一些關於 NPU 底層的環境變數設定,可依照附件表格來變更底層的操作方式。
▼ 如何切換 NPU 或 GPU ?
開啟終端機,設置環境變數 (Device 端)
- 切換至 NPU
$ export USE_GPU_INFERENCE 0- 切換至 GPU
export USE_GPU_INFERENCE 1
▼ 如何使用 Graph Catching?
開啟終端機設置環境變數 (Device 端) , 即可讀取相應的 .nb 檔案。能夠大幅度減少 暖開機(WarmUp-time) 時間。
$ export VIVANTE_VX_CACHE_GRAPH_BINARY_DIR=`pwd`
$ export VIV_VX_ENABLE_CACHE_GRAPH_BINARY=”1”
四. 結語
本文已向讀者闡明 NPU 在機器學習框架 TensorFlow Lite 之各個委託代理的用法,不論是 C/C++ 或是 Python 皆能透過變更代碼或改變參數的方式來選擇不同的硬體來進行模組推理(Inference)。並介紹了如何讓系統顯示 NPU 運行時的相關資訊,像是模組解析的過程之類的訊息。同時,也說明暖開機的運作原理,以及如何產生出 .nb 檔案來縮減暖開機時間。最後,提供一些關於 NPU 的環境變數,讓開發者可以查閱此表格來達到不同的應用目的。比如說 NPU 與 GPU的切換,僅須要透過設置環境變數即可達成。而關於 NPU 的細節介紹,這裡就告一段落了!! 謝謝各位收看 !!
五. 參考文件
[1] 官方文件 - i.MX Machine Learning User's Guide
[2] 官方文件 - ISP and NPU
[3] 官方文件 - i.MX 8M Plus NPU Warmup Time
如有任何相關 NPU 技術問題,歡迎至博文底下留言提問 !!
接下來還會分享更多 NPU 的技術文章 !!敬請期待 【ATU Book-i.MX8 系列 - NPU】 !!

評論