

在開始介紹 MediaTek NeuroPilot 之前,我想先幫各位夥伴們科普一下什麼是 Edge AI。
許多人工智慧仍遠在雲端,且可能無法如你所願,快速地傳送到達終端。夥伴們也許會思考,為什麼不讓人工智慧離你近些呢?
MTK將人工智慧技術應用到你周邊的終端裝置,充分地實現終端人工智慧,這意味著夥伴們無需等待,也無需上網,就能立即享受到人工智慧。
使用上可以得到更快速地回應、更好的隱私保護、更多的功能。
Faster response
Better privacy
More Functionality
然而,為了優化終端人工智慧,MediaTek 為神經網路運算,設計了一個全新的人工智慧處理單元 APU,和 CPU 相比,它可以節省高達 95% 的電力 (SAVE 95% ENERGY CONSUMPTION),讓你能有更多的時間處理更多任務
MTK還建立了一個創新的異構運算架構 (HETEROGENEOUS COMPUTING),能即時導引正確的任務到正確的位置,讓每個處理器都能發揮最佳性能和最大化的能源效率,這就是MTK的終端人工智慧平台 – NeuroPilot
NeuroPilot 支持業界所有主流的人工智慧架構如下列所示。
Google: TENSORFLOW/TENSORFLOW LITE
AMAZON: MXNET
CAFFE
SONY: NNABLA
Other NN Frameworks
如果夥伴們是開發人員,只要開發一次,便可應用 NeuroPilot 到任何可支援的終端裝置。
CROSS PRODUCT
CROSS OPERATING SYSTEM
Android / Linux / RTOS / Others
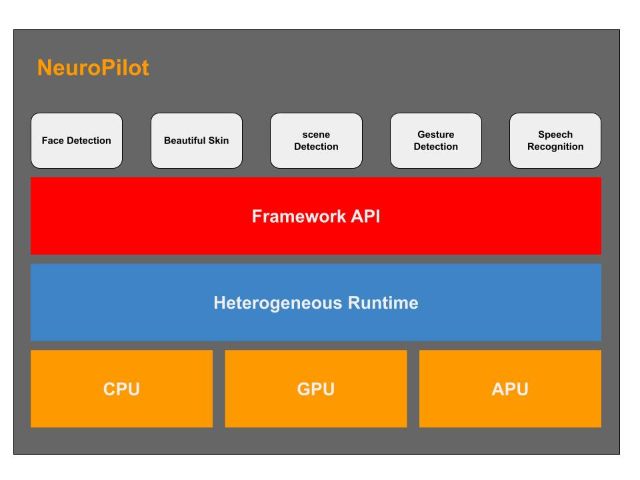
NeuroPilot 大致可分為三個層級,如下圖所示,最頂層是各種應用程序,也是我們日常就能接觸的一些應用,像是一些臉部識別、面部美化、場景檢測、手勢檢測、語音識別等等。
中間層用於程序編寫和異構運算,主要由軟體算法所構置的,包括神經網絡運行(NN Runtime), 異構運行(Heterogeneous Runtime)。
這些基於各別級別的 API 進行程序編寫的框架,我們稱之為 AI framewrok,像 Google 的tensorflow(Lite)、caffe、Amazon 的 MXNet、Sony 的 NNabla 等。
聯發科技的 NeuroPilot 支持市面上主流且常用的所有 AI framework,意思就是說,我們的夥伴們就能夠很方便地在 NeuroPilot 平台上進行程序開發,同時也能夠很好地與雲端對接。
再來最底層是各種硬件處理器 CPU、GPU、APU。
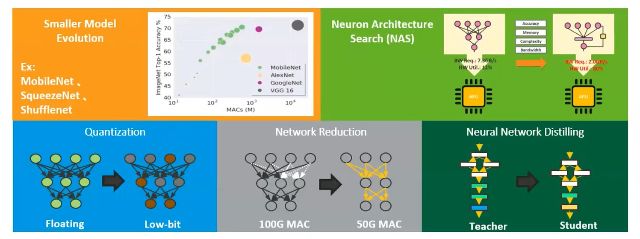
一般情況下,我們在處理這個 model 太大,然後想要把它縮小,做優化來講,有幾個大家比較常用的手法。
我先講一下什麼是優化,優化工具主要專注的地方是在 training 那個階段。會把訓練好的 model 來做優化。夥伴們可能會想,為什麼要在 training 好的 model 來做優化呢?
這是因為我們很多AI model 在訓練好的時候,其實佔用很大的容量,動不動就幾百兆字節。這樣大小的 model 放在設備端來執行的話,可以想像,第一個跑起來會很慢,第二個是非常的耗電。所以我們會用一些手法來做一些優化,讓這個 model 變比較小,比較適合在設備端來執行。
第一個手法是有些 Model 本身就比較小,如下列圖示,而它的準確度,不會因為他 model 小就被影嚮,例如像是我們看到 MobileNet、SqueezeNet 和 Shufflenet,這幾種來執行。
或是我們可以使用程式的方式去探索硬體,知道這個硬體適合什麼樣的 Model在什麼樣的硬體上會跑比較快,這種方法叫做 NAS,Neuron Architecture Search,這個手法,直接用程式去跑,看找什麼樣的Model比較適合的。
另外底下三個手法,它就是用程序,去達成讓 Model 縮小,首先是 Quantization,或是中文我們叫做量化,這樣的手法其實是去改變我們原本 Model 的儲存數字和參數。
把它從 Floating point 這種比較大的格式,轉換成 integer 這種比較小的格式。你可以想像,轉換變小之後,它的 Model也會跟著轉換縮小,縮小之後,這個 Model 就可以在設備端,跑起來比較快,比較省電。
第四個方法,這邊寫到是 Network Reduction, 或者是我們在軟件上稱做 Pruning,中文可能會叫做 剪枝,這個手法我們可以想像它是一個Model壓縮的技術,它可以把一個比較大的Model,壓縮成一個比較小的 Model。
另外也有人用另一個方法,它把一個大的 Model,然後再用一個小的 Model 去學這個大的Model,就是用原本training完 大的 Model,用小Model 去學它,然後最後在設備端上來執行,這是叫做 distilling 的手法。
關於 NeuroPilot 基本的介紹就到此,有興趣的夥伴們,可以隨時與我們探討和研究,謝謝。
評論