

一. 概述
在邊緣運算的重點技術之中,除了簡化複雜的模組架構,來簡化參數量以提高運算速度的這項模組輕量化網路架構技術之外。另一項技術就是各家神經網路框架 (TensorFlow、Pytorch etc…) 的 模組優化 能力,主要探討 TensorFlow Lite 的 訓練後之量化方式(Post-training quantization) 與 感知量化訓練(Quantization-aware Training) ,依序分為上與下兩篇幅,本篇將介紹後者資訊為主。所謂的量化就是將以最小精度的方式,來進行模組推理,使模組應用至各種 Edge Device 之中,並達到足夠成本效益,如下圖所示。順帶一提, 恩智浦 NXP i.MX8M Plus 的 NPU(Neural Processing Unit) 神經處理單元,屬於純整數的 AI 加速器,就僅適用於 8位元的整數運算才能獲得最佳效益 !! 此系列的後續章節,也會利用 NPU 來實現算法加速之目的。
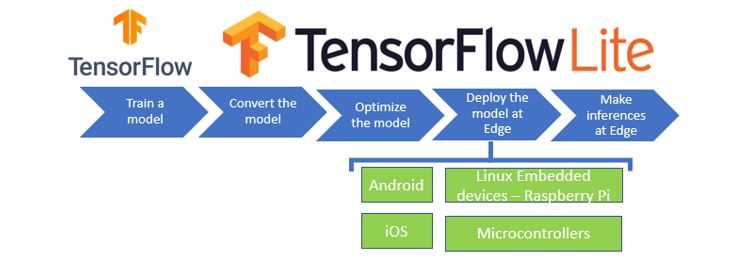
TensorFlow 模型應用概念之示意圖
利用 TensorFlow Lite 量化方式 所構成的 模組 ,就是將訓練完成的輕量化模組,透過量化與優化的方式來提升推理速度 !! 如下模型運作概念圖所示,儲存模型完成後,即可依序執行凍結模型、優化模型到最後輕量化模型 (.tflite),讓模型運行在移動式裝置時可達到最佳化的效果。
※ MobileNet 模組是一種輕量化模組的架構,而此篇重點是如何透過模組量化轉換為輕量化模組(tflite)
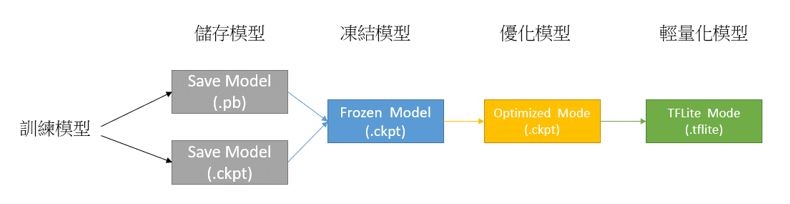
TensorFlow 模型運作概念之示意圖
如下圖所示,本系列是隸屬於 機器學習開發環境 eIQ 之 推理引擎層 (Inference Engines Layer) 中的 TensorFlow Lite 進階系列,故後續將向讀者介紹 “模組量化(下)”
若新讀者欲理解更多人工智慧、機器學習以及深度學習的資訊,可點選查閱下方博文
大大通精彩博文 【ATU Book-i.MX8系列】博文索引
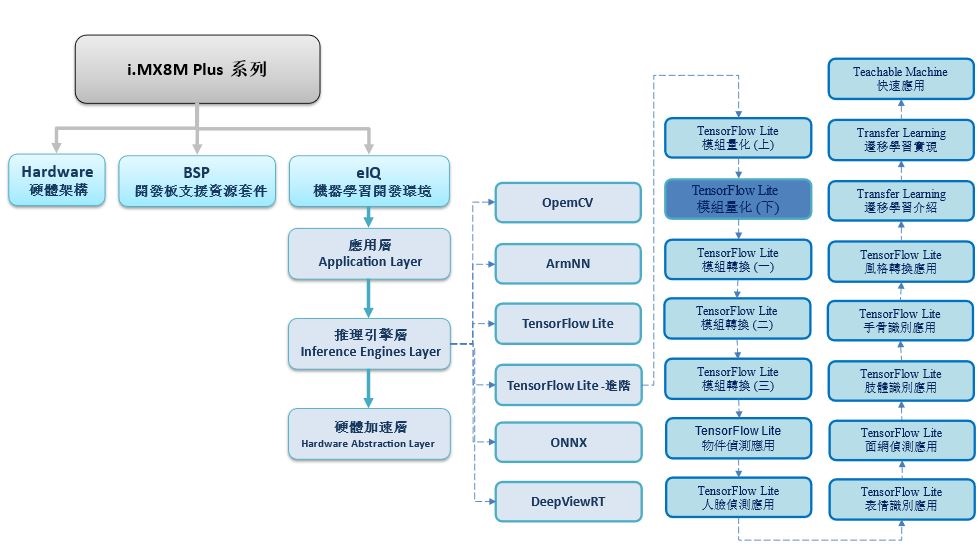
TensorFlow Lite 進階系列博文-文章架構示意圖
二. 量化理論
何謂量化 ? 在此文章是泛指數值程度上的量化,亦指有限範圍的數值表示方式。其作用是為了降低數值資料量與模組大小,來提升傳輸與執行(推理)速度!! 而所謂的訓練後之量化(Post-training quantization) 就是利用訓練完成的模組,再次進行量化的一種優化方式。主要特色就是僅須要儲存後的模組( SaveModel / .h5 /ckpt),且不需要訓練時的資料庫即可量化。
舉例來說,如下圖所示,是須將原本數值分布為 -3e38 到 +3e38 的浮點數型態 float,量化為數值分布 -231 到 231 的整數型態 int ,並以原本數據的最大值與最小值來找出有效的數值範圍,將有一定概率大幅度減少資料量。
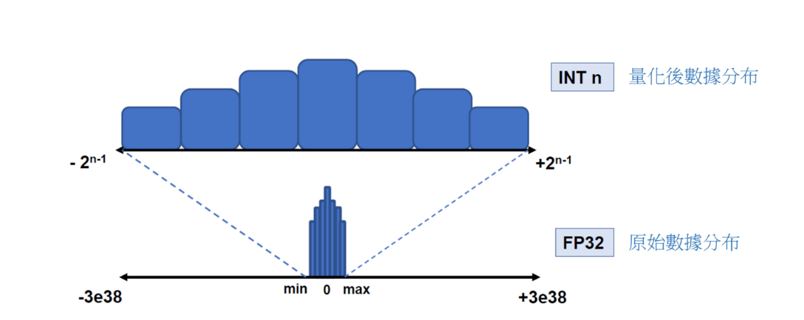
數據量化示意圖
如何量化? 下列以最實際公式進行演示
假設原始數值的範圍為 [-2 : 6.0] 的浮點表示,將其量化至目標範圍 [-128 : 127] 的 8bit 整數範圍
第一步,找出量化後能夠表示的最小刻度
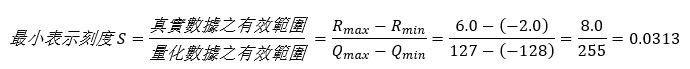
第二步,找出相對應的量化定點值
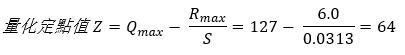
第三步,找出相對應的量化定點值
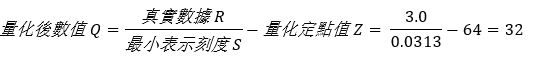
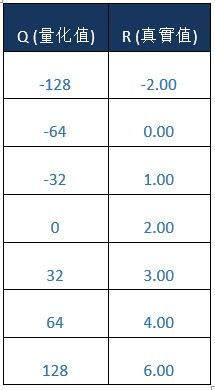
即可找出浮點數為 3.0 時,所對應的量化數值為 32。若將上述量化方式,將浮點數數值範圍量化為整數範圍,即如同下方表格所示。
量化優勢? 劣勢 ? 對於 TensorFlow Lite輕量化的應用而言
優勢:
- 減少模組尺寸:最多能縮減 75% 的大小
- 加快推理速度 : 使用整數計算大幅度提升速度
- 支援硬體較佳 : 能使處理八位元的處理器進行推理
- 傳輸速度提升 : 因模組尺寸縮小,能更獲得更好的傳輸品質
缺點 :
- 精度損失 : 因為數值的表示範圍縮減,故模組的準確度將會大幅度的降低
三. 感知量化訓練(Quantization-aware Training)
感知量化訓練(Quantization-aware Training, QAT) 亦是一種量化手段,其原理與上一小節所介紹的量化方式雷同,目的也是以降低精度的方式,縮小模組所需計算的資料量,來提升模組運算速度,且保持一定準確度的一種優化手段。相較於上一小節所介紹的 訓練後之量化方式(Post-training quantization) 最大的不同,就是需要利用 原生模組 與 訓練集(DataSets) 來作重新訓練,而 感知量化訓練 會於訓練時,去模擬低精度的運算,來保持最佳的模組準確度。
故理論上, 『感知量化訓練量化』 的準確度會來得比 『訓練後之量化方式』 來的準確,如下圖所示 ; 感知量化訓練的模組(QAT Model) 準確度能夠逼近於原生模組(Baseline Model),反之,訓練後之量化方式(Post-Training full quantized Model) 則降低了約莫 0.05 的準確度。但其實該量化方式存在比較多不穩定因素,像是各機器學習框架的轉換、版本不匹配、缺乏正確訓練資料集或是不能微調等等因素,故官方比較推薦使用 『感知量化訓練量化』 來獲得更穩定的量化體驗。
※ 補充說明 : 目前僅應用於 Keras ( TensorFLow 2.X ) 的所建立的模組或 API
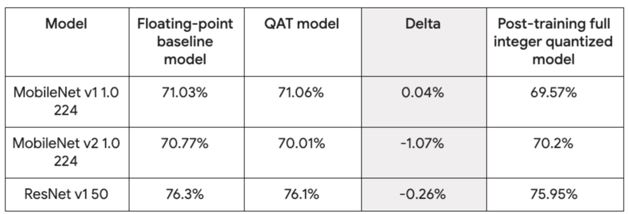
TensorFlow Lite 各種量化方式的準確度示意圖
資料出處 – 官方文件
使用方式 :
大致上 Quantization Aware Training 的應用核心 可以分為四個步驟,分別為建立原生模組、建立感知量化模組、進行感知量化訓練、進行轉換等步驟。
必要套件 :
$ pip install -q tensorflow
$ pip install -q tensorflow-model-optimization
Step 1 : 建立原生模組
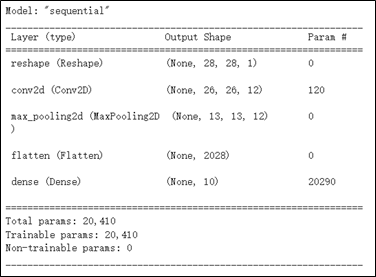
感知量化模型是需要搭配 原生模型 與 原生模型所訓練的資料集。這裡利用 MNIST 手寫識別的範例來進行演示,如下代碼所示 ; 包含模組架構建立,以及利用 MNIST DataSets 進行訓練。
import tempfile
import os
import tensorflow as tf
from tensorflow import keras
# Load MNIST dataset
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
# Define the model architecture.
model = keras.Sequential([
keras.layers.InputLayer(input_shape=(28, 28)),
keras.layers.Reshape(target_shape=(28, 28, 1)),
keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation='relu'),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
# Train the digit classification model
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
model.fit( train_images, train_labels,epochs=1, validation_split=0.1, batch_size=32 )
其原生模組架構,如下圖所示。
Step 2 : 建立感知量化模組 (普通用法)
最簡單的感知量化訓練方式,就是直接利用 Tensorflow Model Optimization 的量化套件進行應用。
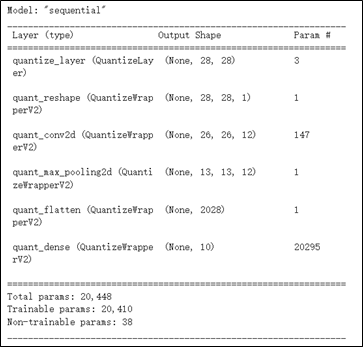
如同下代碼與結果所示,將 原生模組 代入至 quantize_model 量化套件中,即構成感知量化的模組架構 ; 若仔細觀察的話,則會發現架構層的名稱皆冠上 quant 的字眼,也就是程式會去模擬低精度的運算,亦可稱 Fake Quantization 。
import tensorflow_model_optimization as tfmot
quantize_model = tfmot.quantization.keras.quantize_model# q_aware stands for for quantization aware.
q_aware_model = quantize_model(model)
q_aware_model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
q_aware_model.summary()
其感知量化模組架構,如下圖所示。
Step 2 : 建立感知量化模組 (進階用法)
進階的感知量化訓練方式,就是直接利用Tensorflow Model Optimization 的量化套件進行微調,選擇適當的架構層進行量化。
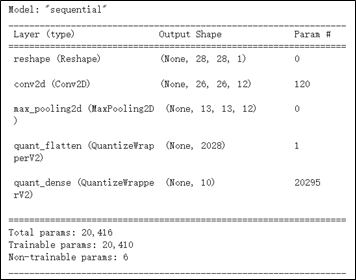
如下代碼所示,將利用 clone_model 複製原生模組(baseline model) 並透過 apply_quantization_to_dense 來選擇須量化的架構層,而此範例僅量化 Dense 架構層。
def apply_quantization_to_dense(layer):
if isinstance(layer, tf.keras.layers.Dense):
return tfmot.quantization.keras.quantize_annotate_layer(layer)
return layer
annotated_model = tf.keras.models.clone_model(
base_model,
clone_function=apply_quantization_to_dense,
)
qat_model = tfmot.quantization.keras.quantize_apply(annotated_model)
qat_model.compile(optimizer='adam', loss=tf.keras.losses.SpareCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])其感知量化模組架構,如下圖所示,請讀者仔細觀察與普通用法的不同,就能夠發現前面幾架構層,以無 quant 的字眼,表示這是原生的架構層。
若欲理解更多進階用法,可以參考官方範例以及 查看可量化的架構層(請搜尋Default8BitQuantizeRegistry 的字眼,查閱所描述的架構層),同理,若欲嘗試量化沒有支援的架構層,可以透過 QuantizeConfig 方式進行量化,可以參考 Medium 網誌的解說 !!
Step 3 : 進行感知量化訓練
接著,需要對 感知量化模組(q_ware_model) 再次進行訓練,得以模擬低精度運算,如下代碼所示。
train_images_subset = train_images[0:1000]
train_labels_subset = train_labels[0:1000]
q_aware_model.fit(train_images_subset, train_labels_subset,batch_size=500, epochs=1, validation_split=0.1)
q_aware_annotate_model.fit(train_images_subset, train_labels_subset,batch_size=500, epochs=1, validation_split=0.1)訓練完成後,即可驗證模組的準確度的表現狀況,如下代碼與結果所示 ; Baseline test accuary 為原始模組所呈現的準確度,反之 Quant test accuracy 為感知量化的準確度 !! 而感知量化的方式略高於 0.02 的準確度,故更好的準確度表現 !!
_, baseline_model_accuracy = model.evaluate(
test_images, test_labels, verbose=0)
_, q_aware_model_accuracy = q_aware_model.evaluate(
test_images, test_labels, verbose=0)
_, q_aware_annotate_model_accuracy = q_aware_annotate_model.evaluate(
test_images, test_labels, verbose=0)
print('Baseline test accuracy:', baseline_model_accuracy)
print('Quant test accuracy:', q_aware_model_accuracy)
print('Quant test accuracy(annotate):', q_aware_annotate_model_accuracy)

Step 4 : 進行轉換
基本上,前面步驟已經完成大致 感知量化訓練 的操作,但因為最終目標是須應用於移動裝置之中。故需要於感知量化訓練且生成新的模組之後,利用上一小節的 訓練後之量化方式(Post-training quantization) 的方式進行量化轉換,如下代碼所示 !! 然而,細心的讀者應該可以發現一些小細節,就是這個代碼又做一次優化,這裡先賣個關子,原因將置於結論再向讀者探討 !!
# quantized_aware_tranning_model(Dynamic)
run_model = tf.function(lambda x: q_aware_model(x))
concrete_func = run_model.get_concrete_function(tf.TensorSpec([1,28,28], model.inputs[0].dtype))
converter = tf.lite.TFLiteConverter.from_concrete_functions([concrete_func])
converter.optimizations = [tf.lite.Optimize.DEFAULT]
quantized_aware_tranning_model_dynamic = converter.convert()
with open("quantized_aware_tranning_model_dynamic.tflite",'wb') as f:
f.write(quantized_aware_tranning_model_dynamic)
print("quantized_aware_tranning_model_dynamic done!!")完成後,會生成對應的 .tflite 檔案,即可直接應用!!
量化使用分析 :
這裡以 MNIST 手寫數字識別模組為基準,將測試原生模組 與 感知量化訓練(普通用法與進階用法) 所生成的模組,來搭配訓練後之量化等轉換方式來驗證準確度為何 !! 同時,也測試經過訓練後之量化的方式,是否對於模組準確度或是應用有何影響? 其測試代碼就如同上一章所介紹的方式,或可以直接查看以及執行運行 Colab 代碼。
實驗測試數據結果 :
其測試準確度數據結果如下 :
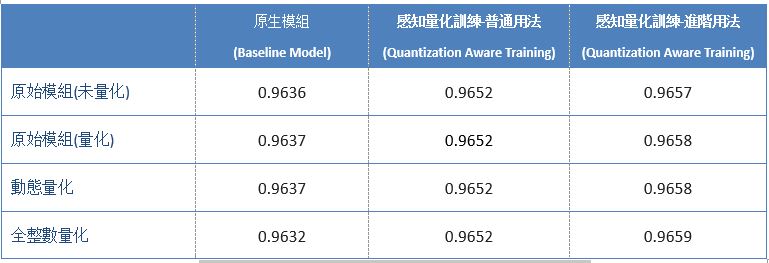
TensorFlow Lite 各種量化轉換之準確度分析
同時,將模組移植至 NXP i.MX8M Plus 並使用 AI 晶片 NPU 來測試推理速度數據結果如下 :
※ 補充說明 : 測試版本為BSP L5.15.5 版本
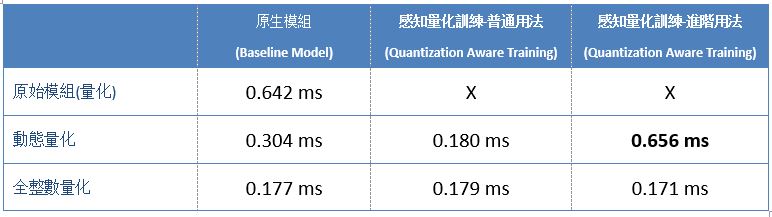
TensorFlow Lite 各種量化轉換之推理速度分析 (NPU)
亦將模組移植至 NXP i.MX8M Plus 並使用 ARM 核心加速(XNNPACK) 來測試推理速度,如下 :
※ 補充說明 : 其中 X 表示模組無法正常運行,暫不列入考量
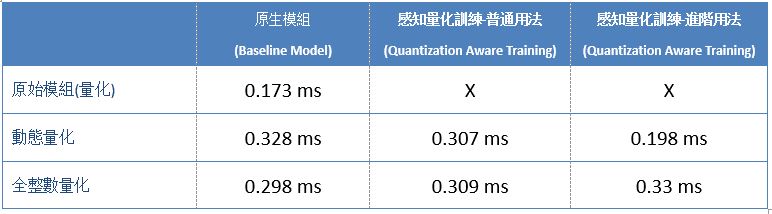
TensorFlow Lite 各種量化轉換之推理速度分析 (ARM)
四. 結語
依目前實驗結果而論,感知量化訓練(Quantization Aware Training) 能夠盡可能去逼近原始模組的準確度,甚至還可能有些許的小幅度提升。而就推理速度來看,感知量化訓練的普通用法其實相當於訓練後之量化的全整數量化之結果,也表示模組內的參數已轉換為低精度的表示方式 !! 換句話說,若實現過 感知量化訓練 的優化則不必多此一舉再做一次訓練後之量化的優化。但礙於硬體加速器或處理器的不同,可能會出現各式各樣的問題,就如同上述表格中的 X ,這就代表感知量化訓練所生成的模組,仍有一定機率不能順利運行於 NPU 上。故重新結合訓練後之量化方式來達到更加的應用體驗 !! 此外,讀者不仿思考一下,為何感知量化訓練的普通用法與進階用法,所呈現的推理速度表現會有落差 ? 其實此結果是完全符合,上述所向各位描述的一致,也就是進階用法僅量化了完全連接層(Dense) 一個架構層而已,自然表現就會比普通用法來得慢 !! 最後,探討一下是否推薦使用『感知量化訓練』 來進行優化? 以作者角度而言,若是開發者剛好使用 Keras 框架來開發模組的話,是個很棒的選擇 !! 而事實上,每個神經網路框架都有擁護者,不可能所有人都用此框架開發。故對於活用度而言,感知量化訓練略顯於不足,故仍推薦先活用 訓練後之量化的方式 進行優化 !! 倘若,有閒之時再將框架、模組、算法移植至 Keras 來實現感知量化訓練,才能發會最大的應用效益 !! 因此後續章節,將會向各位介紹不同的神經網路或深度學習框架之間的轉換,敬請期待 !!
五. 參考文件
[1] 官方文件 - i.MX Machine Learning User's Guide pdf
[2] 官方文件 - TensorFlow Lite 轉換工具
[3] 官方文件 - Quantization Aware Training
[4] 官方文件 - Colab
[5] 第三方文件 - Tensorflow模型量化(Quantization)原理及其实现方法
如有任何相關 TensorFlow Lite 進階技術問題,歡迎至博文底下留言提問 !!
接下來還會分享更多 TensorFlow Lite 進階文章 !!敬請期待 【ATU Book-i.MX8系列 – TFLite 進階】 !!
評論