

► 前言
要學習AI但硬體計算資源有限,可以從高維度數據中提取關鍵特徵,或如何降低數據的維度以節省計算資源,這就是自編碼器(AutoEncoder)發揮作用的地方。通過編碼器和解碼器的結構,AutoEncoder能夠將輸入數據壓縮成較低維度的表示,同時盡可能地重構出原始數據。本篇博文,我們將介紹AutoEncoder及其優點及缺點,透過PyTorch 搭建一個簡單的 AutoEncoder範例。
► 介紹
AutoEncoder是一種人工神經網路,主要用於無監督學習和特徵學習。它可以將輸入數據壓縮成較低維度的表示,然後再將其解壓縮成一個與原始數據相似的輸出。
AutoEncoder 架構圖如下: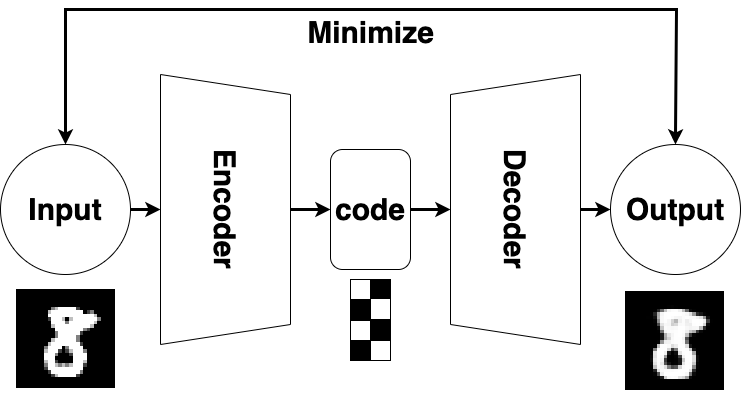
AutoEncoder架構分成兩大部分:編碼器(Encoder)和解碼器(Decoder)。
- 編碼器(Encoder):編碼器將輸入數據轉換為較低維度的表示。
- 解碼器(Decoder):解碼器則將編碼的表示轉換回原始輸入數據。
AutoEncoder的訓練過程涉及最小化重構誤差,即重構的輸出與原始輸入之間的差異。通常使用重構誤差的平方差(如均方差)作為損失函數,並使用反向傳播算法進行優化。
AutoEncoder能夠學習數據的重要特徵,並在解碼過程中生成近似的輸入數據。這使得AutoEncoder應用包括特徵提取、去噪、降維和生成模型等。通過適當的維度減少,它可以幫助降低數據的複雜性,提高效能和計算效率,並能夠生成與訓練數據相似的新數據樣本,如圖像、音頻等。
► AutoEncoder優點
- 數據的降維,減少計算量和存儲空間。
- 數據的去噪,通過重建輸入來恢復原始信號。
- 數據的生成,通過採樣隱藏表示來產生新的數據。
- 數據的特徵學習,通過提取隱藏表示來獲得數據的抽象特徵。
► AutoEncoder缺點
- 可能會過度壓縮數據,導致信息的丟失或失真。
- 可能會過度擬合數據,導致泛化能力差或無法處理異常值。
- 可能會難以訓練,尤其是當隱藏層很深或很寬時,需要調整多個超參數和正則化項。
- 可能會難以解釋,尤其是當隱藏表示是非線性或高度非結構化時,需要使用可視化或其他方法來理解其含義。
► 程式碼範例
使用 PyTorch 搭建一個簡單的 AutoEncoder 模型的程式碼示例,它可以對MNIST數字圖像進行重建:
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 設定超參數
batch_size = 128
num_epochs = 10
learning_rate = 0.001
hidden_size = 64 # 編碼的大小
# 加載MNIST數據集
transform = torchvision.transforms.ToTensor() # 將圖像轉換為張量
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 定義Autoencoder模型
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# 編碼器
self.encoder = nn.Sequential(
nn.Linear(28*28, 256),
nn.ReLU(),
nn.Linear(256, hidden_size),
nn.ReLU()
)
# 解碼器
self.decoder = nn.Sequential(
nn.Linear(hidden_size, 256),
nn.ReLU(),
nn.Linear(256, 28*28),
nn.Sigmoid()
)
def forward(self, x):
# 將輸入張量展平為一維向量
x = x.view(-1, 28*28)
# 獲得編碼
code = self.encoder(x)
# 獲得重建
out = self.decoder(code)
# 將輸出張量恢復為原始形狀
out = out.view(-1, 1, 28, 28)
return out
# 創建模型實例並移動到設備(CPU或GPU)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = Autoencoder().to(device)
# 定義損失函數和優化器
criterion = nn.MSELoss() # 使用均方誤差作為損失函數
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # 使用Adam作為優化器
# 訓練模型
for epoch in range(num_epochs):
train_loss = 0.0 # 紀錄訓練集上的損失
for data in train_loader:
inputs, _ = data # 只需要圖像,不需要標籤
inputs = inputs.to(device) # 移動到設備
optimizer.zero_grad() # 清零梯度
outputs = model(inputs) # 前向傳播
loss = criterion(outputs, inputs) # 計算損失
loss.backward() # 反向傳播
optimizer.step() # 更新參數
train_loss += loss.item() # 累加損失
print(f'Epoch {epoch+1}, Train loss: {train_loss/len(train_loader):.4f}') # 打印平均訓練損失
# 測試模型並可視化結果
test_loss = 0.0
with torch.no_grad(): # 不需要計算梯度
for data in test_loader:
inputs, _ = data
inputs = inputs.to(device)
outputs = model(inputs)
loss = criterion(outputs, inputs)
test_loss += loss.item()
print(f'Test loss: {test_loss/len(test_loader):.4f}')
# 選擇10張圖像並顯示它們的原始和重建版本
num_images = 10
images = inputs[:num_images]
outputs = outputs[:num_images]
# 顯示結果
fig, axes = plt.subplots(nrows=2, ncols=num_images, figsize=(15,4))
for i in range(num_images):
axes[0][i].imshow(images[i].squeeze().cpu().numpy(), cmap='gray')
axes[0][i].axis('off')
axes[1][i].imshow(outputs[i].squeeze().cpu().numpy(), cmap='gray')
axes[1][i].axis('off')
plt.show()
► 結果顯示

► 小結
透過以上介紹相信大致上已經了解AutoEncoder的效果,希望本文能為你提供啟發和指導,讓你能夠在實際應用中充分發揮AutoEncoder的應用,若還有不了解的部分可以看參考資料的網站,本篇博文就到這,下次見。
► 參考資料
► Q&A
問:AutoEncoder是一種有監督學習還是無監督學習模型?
答:AutoEncoder是一種無監督學習模型。它不需要標註的目標變量來進行訓練,而是通過最小化輸入與重構輸出之間的誤差來學習數據的特徵。
問:AutoEncoder的工作原理是什麼?
答:工作原理是通過將輸入數據編碼為較低維度的表示,然後從該表示中解碼重構出原始輸入數據。它由編碼器和解碼器組成,並透過最小化重構誤差來學習數據的特徵和結構。
問:AutoEncoder的應用有哪些?
答:包括特徵提取、降維、去噪和生成模型等。它可以幫助從數據中提取重要特徵、減少數據的維度、去除噪聲,還可以用於生成新的數據樣本,如圖像、音頻等。
問:AutoEncoder與主成分分析(PCA)有什麼關聯?
答:有一定的關聯。它們都可以用於數據的降維,但AutoEncoder在某些情況下可以學習到比PCA更強大的非線性特徵表示。AutoEncoder的編碼器和解碼器組成了一個神經網絡,它具有更強的擬合能力,可以捕捉到數據中更複雜的特徵。
問:AutoEncoder是否可以用於有標註數據的監督學習?
答:雖然AutoEncoder是一種無監督學習模型,但它也可以與監督學習相結合。例如,可以使用AutoEncoder進行無監督的特徵學習,然後將編碼表示作為輸入餵入一個監督學習模型,以進行後續的監督學習任務。
評論