

一. 概述
在邊緣運算的重點技術之中,模組輕量化網路架構 是不可或缺的一環,如何高效的利用硬體資源來達到最佳目標,特別是在效能與準確度的衡量上,是個非常有趣的議題。此章節再來探討深度學習熱門的研究項目之一 人臉關鍵點偵測(Facial KeyPoints Detection) ,主要用於預測人的臉部特徵點位置,可衍伸應用至分析表情、人臉輪廓偵測、人臉替換等等。而具代表性的研究項目為 Dlib、DAN、Facemesh 等等,本範例採用 Google 發佈的 FaceMesh 結合 輕量化網路架構 MobileNet 作為應用主軸 ,後續將介紹演算法的基本概念。
若新讀者欲理解更多人工智慧、機器學習以及深度學習的資訊,可點選查閱下方博文
大大通精彩博文 【ATU Book-i.MX8系列】博文索引
TensorFlow Lite 進階系列博文-文章架構示意圖
二. 算法介紹
神經網路架構探討 :
人臉關鍵點偵測並非著重於架構的改變,更重要的是如何運用特徵。如下圖所示,左側為 Facial keypoint 的典型做法,以 68 點來描述面部的特徵。右側則是 FaceMesh的新穎做法,以 468 點來描述面部的特徵。此外 FaceMesh 也是利用 MobileNet 架構來預測這 468 個特徵點的位置資訊。FaceMesh 於一般的 Facial keypoint 概念不同的地方是引入的 3D 特徵點,取得原本偵測熱圖的概念 (可查看後續 Pose Estimation 章節)。故預測後得到參數應為特徵點的像素坐標 (x,y),網格重心的深度值為 z ,共三個維度。
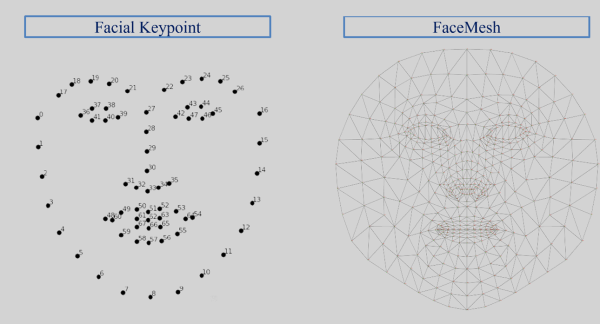
Facial keypoint 與 FaceMesh 特徵點概念示意圖
圖片來源 - MediaPipe
三. 算法實現
Google 官方有提供效果極佳的 facemesh.tflite 模組,故利用 TensorFlow Lite 與 ONNX 的轉換,將 MediaPipe 團隊提供的模組應用至 i.MX8M Plus 平台來實現所謂的 面網偵測(FaceMesh) 。
範例連結 : https://google.github.io/mediapipe/solutions/face_mesh.html
實現步驟如下:
第一步 : 開啟 Colab 設定環境
%tensorflow_version 2.x第二步 : 下載轉換套件
! pip install tf2onnx
! pip install onnx-tf
第三步 : 下載 MediaPipe 的 FaceMesh 模組
! cd /root
! git clone https://github.com/google/mediapipe
! cp /root/mediapipe/mediapipe/modules/face_landmark/face_landmark.tflite /root/facemesh.tflite
第四步 : TensorFlow Lite 轉為 ONNX 格式
! python -m tf2onnx.convert --opset 9 --tflite /root/facemesh.tflite --output /root/facemesh.onnx第五步 : ONNX 轉為 SavedModel 格式
! onnx-tf convert -i /root/facemesh.onnx -o /root/facemesh第六步 : TensorFlow Lite 轉換
import tensorflow as tf
import numpy as np
def representative_dataset_gen():
for _ in range(250):
yield [np.random.uniform(0.0, 1.0, size=(1, 192, 192, 3)).astype(np.float32)]
converter = tf.lite.TFLiteConverter.from_saved_model("/root/facemesh")
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS,tf.lite.OpsSet.SELECT_TF_OPS]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.float32
converter.representative_dataset = representative_dataset_gen
tflite_model = converter.convert()
with open('/root/facemesh_uint8.tflite','wb') as f:
f.write(tflite_model)第七步 : FaceMesh 範例實現 (於 i.MX8M Plus 撰寫運行)
需搭配人臉偵測找出人臉位置,若相關模型請查看 ”人臉偵測(face Detection) ” 章節
import cv2
import numpy as np
from tflite_runtime.interpreter import Interpreter
# 載入人臉檢測器(face detector) , 解析 tensorflow lite 檔案
interpreterFaceExtractor = Interpreter(model_path='mobilenetssd_uint8_face.tflite')
interpreterFaceExtractor.allocate_tensors()
input_details = interpreterFaceExtractor.get_input_details()output_details = interpreterFaceExtractor.get_output_details()
width = input_details[0]['shape'][2]
height = input_details[0]['shape'][1]
# 載入面網檢測器(facemesh detector) , 解析 tensorflow lite 檔案
interpreterFaceMesh = Interpreter(model_path='/root/facemesh_uint8.tflite')
interpreterFaceMesh.allocate_tensors()
facemesh_input_details = interpreterFaceMesh.get_input_details()
facemesh_output_details = interpreterFaceMesh.get_output_details()
facemesh_width = facemesh_input_details[0]['shape'][1]
facemesh_height = facemesh_input_details[0]['shape'][2]
# 載入影像資訊,並設置張量 Tensor
frame = cv2.imread("/root/YangMi.jpg")
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_resized = cv2.resize(frame_rgb/255, (width, height))
input_data = np.expand_dims(frame_resized, axis=0)
# 檢測出人臉位置資訊
interpreterFaceExtractor.set_tensor(input_details[0]['index'], input_data)
interpreterFaceExtractor.invoke()
detection_boxes = interpreterFaceExtractor.get_tensor(output_details[0]['index'])
detection_classes = interpreterFaceExtractor.get_tensor(output_details[1]['index'])
detection_scores = interpreterFaceExtractor.get_tensor(output_details[2]['index'])
num_boxes = interpreterFaceExtractor.get_tensor(output_details[3]['index'])
# 檢測每一個人臉
for i in range(1):
if detection_scores[0, i] > .5:
# 人臉位置
x = detection_boxes[0, i, [1, 3]] * frame_rgb.shape[1]
y = detection_boxes[0, i, [0, 2]] * frame_rgb.shape[0]
y[1] = y[1] + 15 # offset, 因人臉偵測給予的框架之下巴範圍過少
cv2.rectangle(frame, (x[0], y[0]), (x[1], y[1]), (0, 255, 0), 2)
# 人臉位置資訊整合
roi_x0 = max(0, np.floor(x[0] + 0.5).astype('int32'))
roi_y0 = max(0, np.floor(y[0] + 0.5).astype('int32'))
roi_x1 = min(frame.shape[1], np.floor(x[1] + 0.5).astype('int32'))
roi_y1 = min(frame.shape[0], np.floor(y[1] + 0.5).astype('int32'))
# 感興趣區域 (擷取人臉)
roi = frame_rgb[ roi_y0 : roi_y1, roi_x0 : roi_x1, :]
# 設置來源資料至解譯器
roi_resized = cv2.resize(roi, (facemesh_width, facemesh_height))
facemesh_input_data = np.expand_dims(roi_resized.astype("uint8"), axis=0)
interpreterFaceMesh.set_tensor(facemesh_input_details[0]['index'], facemesh_input_data)
# 面網偵測
interpreterFaceMesh.invoke()
# 畫出面網
mesh = interpreterFaceMesh.get_tensor(facemesh_output_details[1]['index']).reshape(468, 3) # 特徵點
size_rate = [roi.shape[1]/facemesh_width, roi.shape[0]/facemesh_height]
for pt in mesh:
x = int(roi_x0 + pt[0]*size_rate[0])
y = int(roi_y0 + pt[1]*size_rate[1])
cv2.circle(frame, ( x ,y ), 1, (0, 0, 255), 1)
cv2.imshow('facemesh',frame)
cv2.waitKey(0)
Face mesh 實現結果呈現
如下圖所示,成功檢測出臉部面網資訊。
在 i.MX8M Plus 的 NPU 處理器 推理時間(Inference Time) 約 2.91 ms。

四. 結語
面網偵測應用 (FaceMesh) 通常需要搭配 人臉偵測(Face Detection) 來作應用。也就是偵測到人臉的位置後,將局部會特徵交付給面網偵測模組進行特徵提取,才能將準確度應用最大化。最後利用所檢測到的 68 個臉部特徵點來作後續的判斷機制,即可以實現疲勞駕駛或是閉眼、張口檢測等等應用。目前運行在 i.MX8MP 的 Vivante VIP8000 NPU,其推理時間可達每秒 2.91 ms 的處理速度,約 330 張 FPS,以及在正面臉部檢測時,有不錯的檢測率 。由於此範例屬於複合式的應用,故實際花費時間應該為人臉與面網偵測的花費時間,粗估計算為 10 ms + N * ( 3 ms ) ,其中 N 為偵測到的人臉數量。下一章節將會介紹熱門應用之一的 “肢體識別(Pose Estimation)” ,敬請期待 !!。
五. 參考文件
[1] SSD: Single Shot MultiBox Detector
[2] SSD-Tensorflow
[3] Single Shot MultiBox Detector (SSD) 論文閱讀
[4] ssd-mobilenet v1 演算法結構及程式碼介紹
[5] Get models for TensorFlow Lite
[6] widerface-to-tfrecord
[7] Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs
[8] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
[9] MediaPipe Face Mesh
如有任何相關 TensorFlow Lite 進階技術問題,歡迎至博文底下留言提問 !!
接下來還會分享更多 TensorFlow Lite 進階文章 !!敬請期待 【ATU Book-i.MX8系列 – TFLite 進階】 !!

評論