

一、概述
近年來,電腦視覺(Computer Vision) 領域迎來了重大改革,從過去一個一個從像素處理(Pixel) 的方式,已經轉變成由「大數據(Big Data)」來統計出所謂「模組(Model) 」的 深度學習(Deep Learning) 應用方式。更何況是顛覆人類想像的生成式 AI ( Generative AI ) 與 ChatGPT 、可說是 人工智能(Artificial Intelligence) 的時代已經全面來臨,讓周邊的設備智能化已經不是遙不可及的夢想 !! 然而,過去無數學者、研究員、工程師致力研發的系統,現今僅須透過一些簡單的方法就能輕鬆實現,並配合恩智浦 NXP 搭載 神經網路處理器(Neural Processing Unit, NPU) 的 i.MX 93 平台,即可快速實現成終端產品!! 此文章將專注於 Arm 針對 Ethos-U NPU 所設計的開發工具進行深入介紹 !!
如何建立 NXP 嵌入式系統的開發環境, 讀者可以閱讀此 【ATU Book - i.MX8系列 - OS】NXP i.MX Linux BSP 開發環境架設 來快速佈署恩智浦 NXP i.MX9 系列的開發環境,透過此博文或 ATU 一部小編的系列博文,即可輕鬆實現任何有關 i.MX9 的環境架設 !! 或是想要更快速進入到 NXP 平台的實作中,可以至官方網站下載官方發行的 Linux 映像檔(Image)。
Note : 目前作者測試的版本為 BSP L6.1.55_2.2.0
Embedded Linux for i.MX Applications Processors | NXP Semiconductors

Arm Vela Tool 使用示意圖
由於 Arm Ethos-U 系列的 NPU 設計於 8 位元 或 16 位元資料型態,因此建議用戶先透過 Tensorflow 所提供的量化方式,或是 NXP 的 eIQ toolkit 進行模組量化與轉換,並於產生出 tflite 檔案後。即可搭配 Arm vela 工具,特別針對 Ethos-U 的 NPU 進行最佳化配置,舉例 : 以 尺寸大小 或是 性能方面 來進行最佳化配置,或是自行撰寫配置檔。故給予相當自由的操作方式,讓開發者有更多的應用手段。此外,能夠顯示模組的計算圖、運算元、排程、效能等等重要開發資訊! 因此 vela tool是套相當值得學習應用的開發工具 !
二、安裝 Vela 工具
由於 Yocto BSP 已內建 Vela 工具,因此這裡將介紹如何安裝至個人 PC 上 (Linux),幫助開發者加速開發
(1) 從 github 下載套件
$ git clone https://github.com/nxp-imx/ethos-u-vela.git
(2) 安裝 vela tool
$ cd ethos-u-vela
$ git checkout lf-6.6.3_1.0.0
$ pip3 install .
如上操作,即可使用 vela 工具。
三、使用 Vela 工具
專門用於 Arm Ethos-U NPU 的開發工具,可以提供數種優化方式,能夠幫助開發者更有效的應用模組。
1. 基本訊息
(1) vela tool版本資訊 :
$ vela --version

(2) vela api版本資訊 :
$ vela --api-version

(3) 運算元(operator) 清單 :
$ vela --supported-ops-report

(4) Config 資訊 :
$ vela --list-config-files

(5) 設定輸出的資料夾 :
$ vela <model>.tflite --output-dir=<Folder>
輸出的模組與檔案,將會導入該資料夾

(6) 產生 debug 的檔案:
$ vela <model>.tflite --output-dir=<Folder> --enable-debug-db

將會產出 *_debug.xml 檔案 ,並允許追蹤從輸入網路圖到輸出命令流的最佳化。
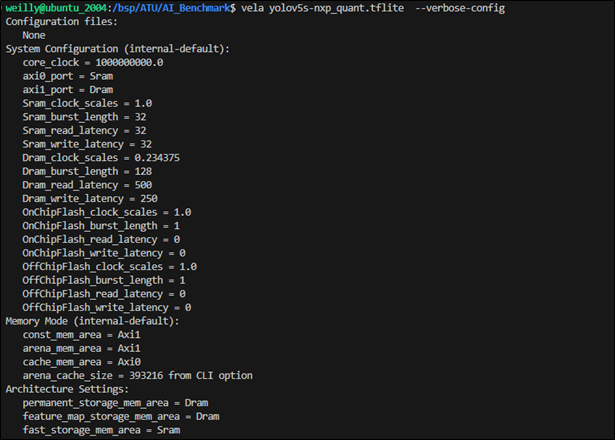
(7) 顯示模組操作時所定義的系統設定值與記憶體模式
$ vela <model>.tflite --verbose-config
2. 顯示訊息
(1) 顯示模組的架構圖或運算圖(Graph)
$ vela <model>.tflite --verbose-graph
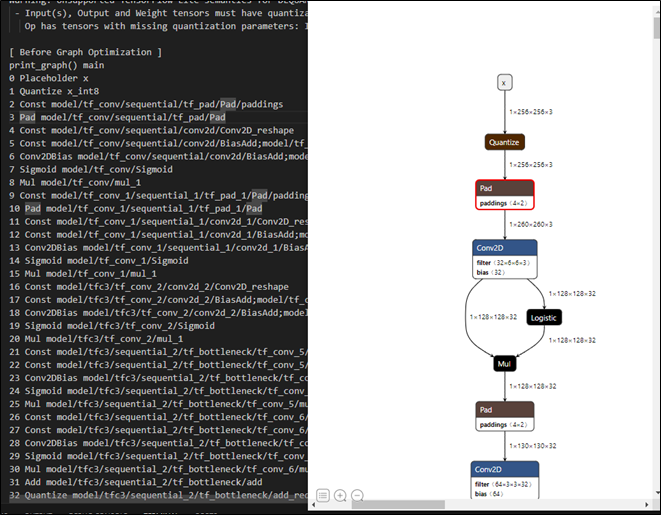
Note : 同時,列出透過 vela 工具優化後的架構圖或是計算圖。
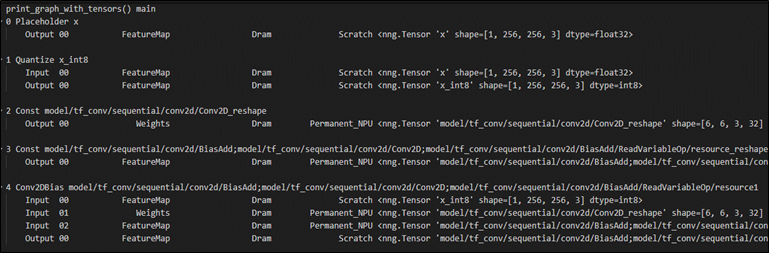
(2) 顯示每個 張量(Tensor) 訊息
$ vela <model>.tflite --verbose-graph
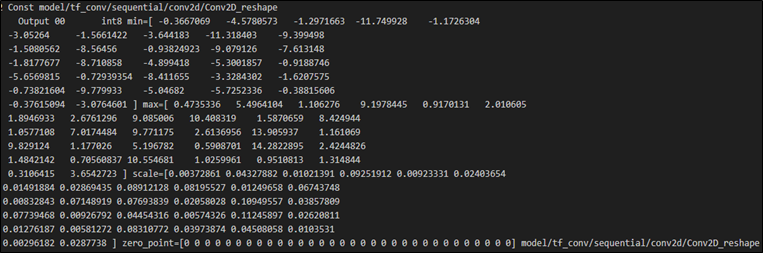
(3) 顯示每個 運算元(Operator) 的權重參數與資料型態
$ vela <model>.tflite --verbose-graph
(4) 顯示 運算子(Operator) 訊息
$ vela <model>.tflite --verbose-operators
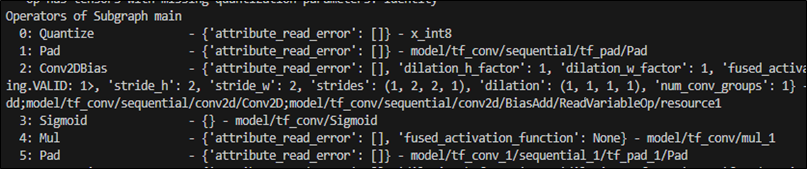
(5) 顯示 運算子(Operations) 訊息 – 使用 NPU / CPU 的訊息
$ vela <model>.tflite --show-cpu-operations
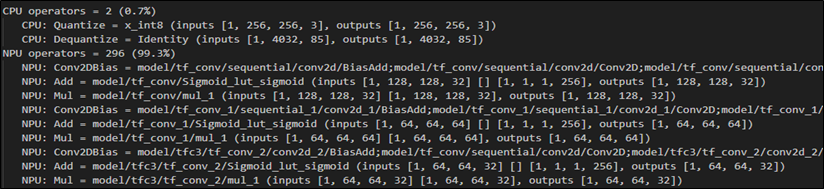
(6) 顯示 效能(Peromance) 訊息
$ vela <model>.tflite --verbose-performance

(7) 顯示 程式段落(Progress) 訊息
$ vela <model>.tflite --verbose-progress
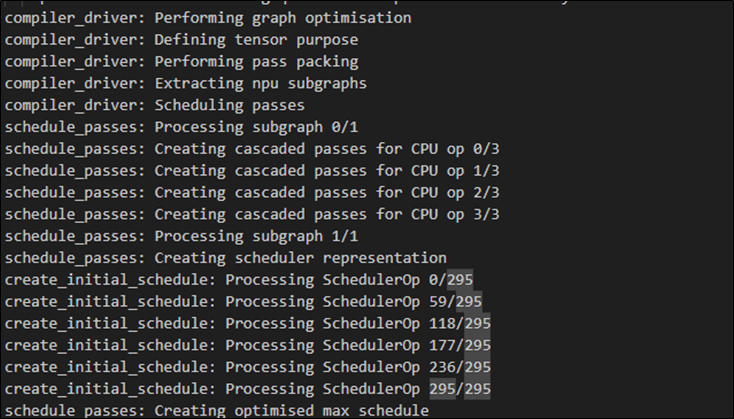
(8) 顯示 排程(Schedule) 訊息
$ vela <model>.tflite --verbose-schedule
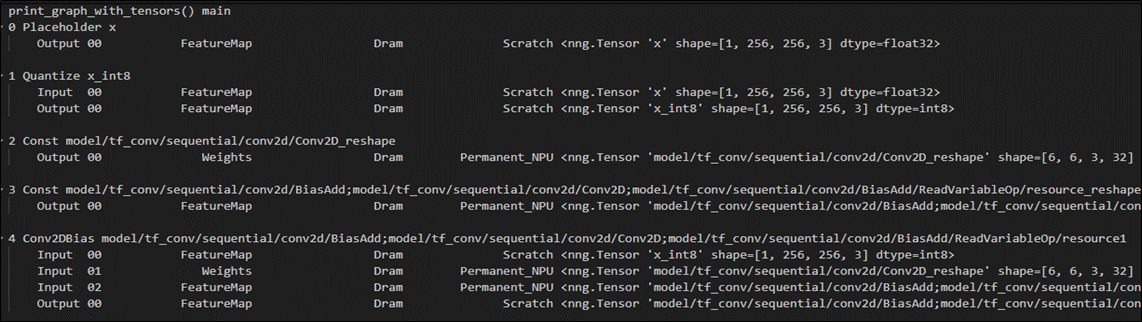
(9) 顯示 程式段落(Progress) 訊息
$ vela <model>.tflite --verbose-progress
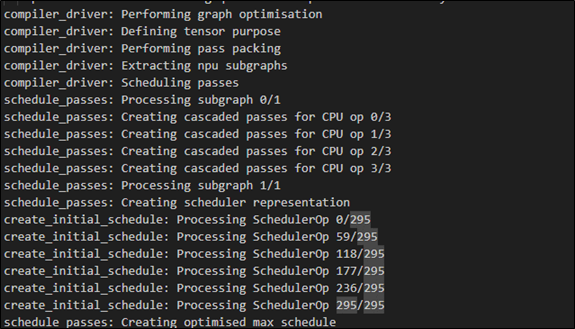
(10) 顯示 計算編譯器執行操作的時間
$ vela <model>.tflite --timing

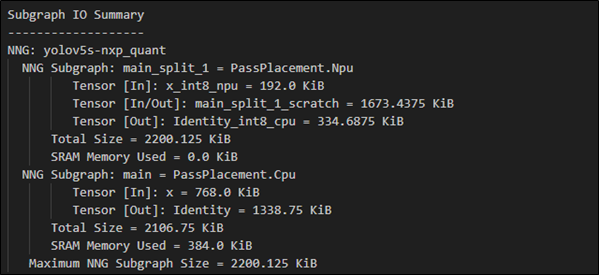
(11) 顯示 NPU 與 CPU 各別輸出/輸入的張量(Tensor) 摘要資訊
$ vela <model>.tflite --show-subgraph-io-summary
3. 編譯設定
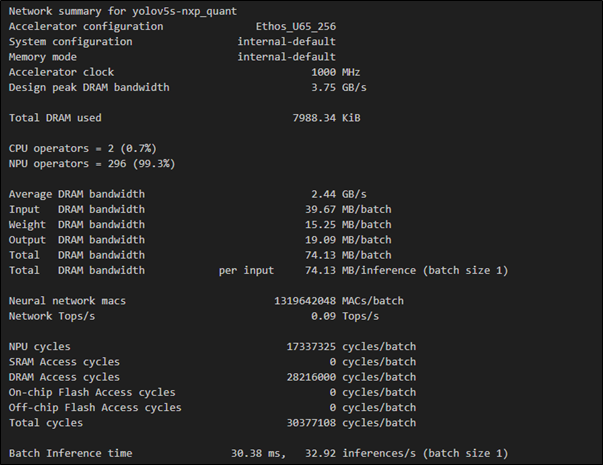
(1) 對於 尺寸(Size) 進行模組最佳化
$ vela <model>.tflite --optimise Size
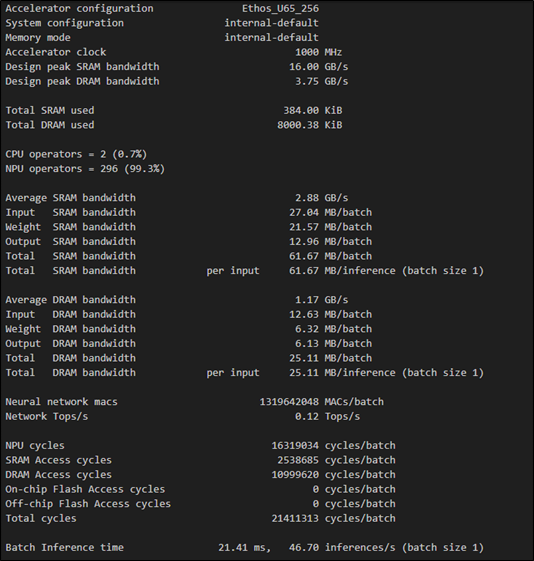
(2) 對於 性能(Performance) 進行模組最佳化
$ vela <model>.tflite --optimise Performance
(3) 對於 性能(Performance) 進行模組最佳化 – 快取(Cache) 限制
$ vela <model>.tflite --optimise Performance --arena-cache-size 3000
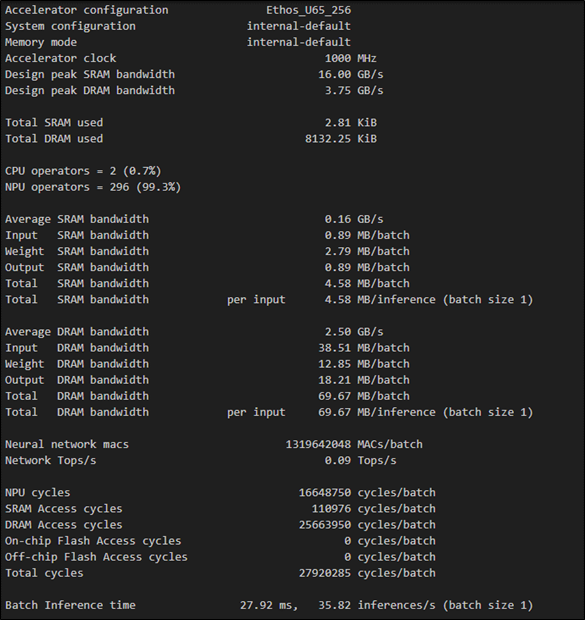
Note : 限制快取(Cache) 的使用量
(4) 對於 張量(Tensor) 選擇 CPU / NPU 的分配演算法 [ Greedy, LinearAlloc, HillClimb ]
$ vela <model>.tflite --tensor-allocator=LinearAlloc
(5) 對於 NPU 核心操作間,區塊依賴延遲最大值 [ 0, 1, 2, 3 ]
$ vela <model>.tflite --max-block-dependency 0
Note : 數值越低、延遲越長
(6) 設置遞迴限制
$ vela <model>.tflite --recursion-limit 2000
(7) 設置 HillClimb 最大迭代次數
$ vela <model>.tflite --hillclimb-max-iterations 1000
(8) 進行設置 ini 檔案來實現模組最佳化
$ vela <model>.tflite --config <file>.ini
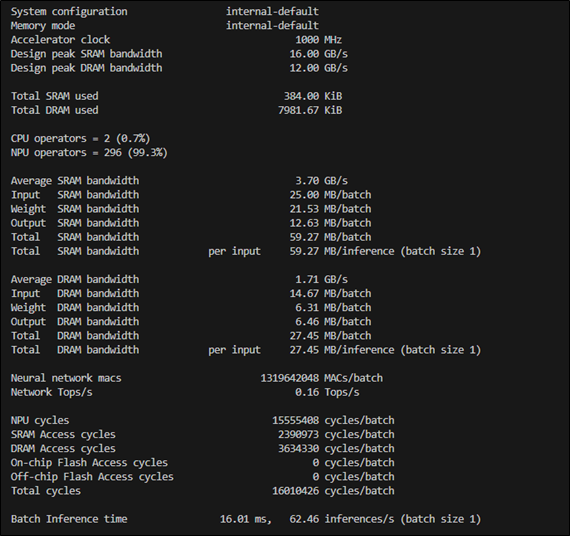
可參考此檔案 Vela.ini
(9) 設置 系統配置(System Config)
$ vela <model>.tflite --config <file>.ini --system-config Ethos_U65_Client_Server
官網資訊 : 點選

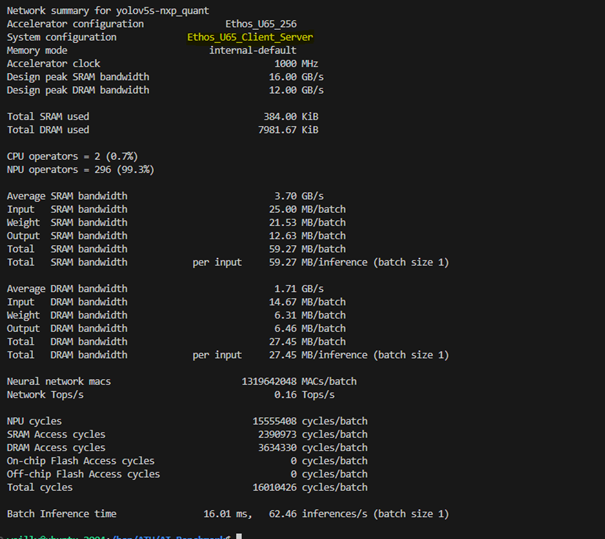
(10) 設置 記憶體配置(System Config)
$ vela <model>.tflite --config <file>.ini --memory-mode Dedicated_Sram
官網資訊 : 點選

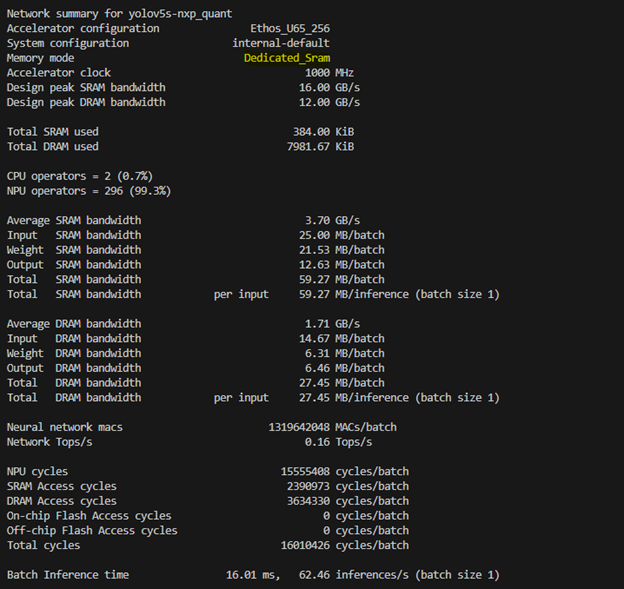
在 Ethos-U65 NPU 的設計裡面,有三種記憶體架構
容量大小為 256KB ( 128KB + 128KB ),其用途作為 Cortex-M 傳輸資料時使用。
b. OCRAM ( On-Chip RAM )
容量大小為 640KB,其中 256 KB 分配給 ATF 機制,用於 Cortex-A 傳輸資料時使用,其餘 384 KB 則保留給予 NPU 作為權重暫存使用
c. DRAM
容量大小為 2GB,用於Cortex-A和Cortex-M之間的 DMA 機制。
主要使用兩種記憶體模式
a. Sram_Only 模式
不使用 DRAM,模型數據和 TensorArena 記憶體都分配在 OCRAM 中。
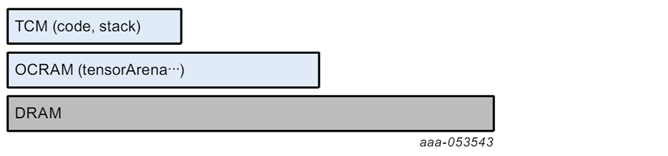
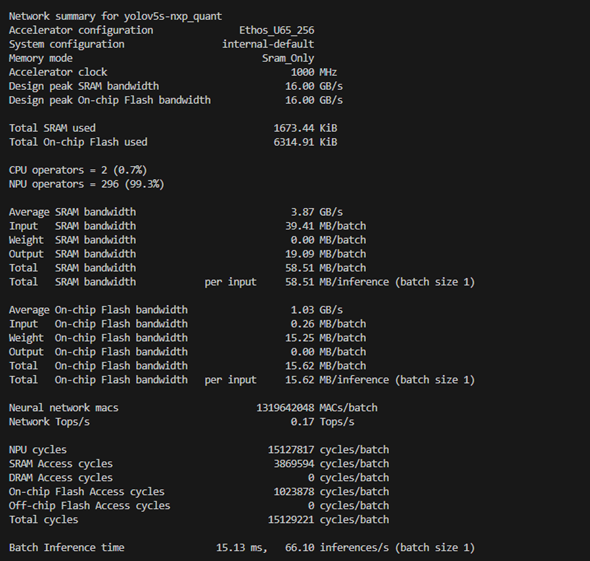
$ vela <model>.tflite --config <file>.ini --system-config Ethos_U65_High_End --memory-mode Sram_Only
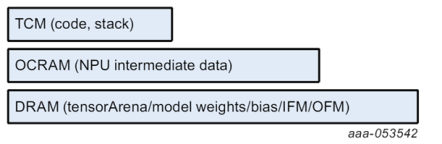
b. Dedicated_Sram 模式
模型數據和 TensorArena分配在DRAM 中,OCRAM 用作 NPU 緩存。
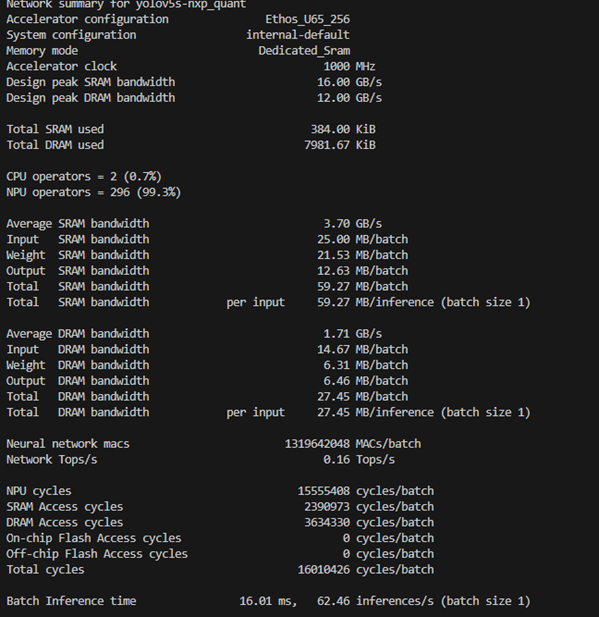
四、結語
近年無數學者、研究員與業者致力於研究物件偵測相關的應用,如前篇文章僅需要利用簡單幾個步驟就完成一個簡單的『 YOLOv5 物件識別 』,且僅需短短幾個小時即可訓練出模型,相比與過去實在天壤之别。因此如何部屬至各個硬體平台端就是『落地的關鍵指標之一』 ; 本篇文章以『NXP i.MX 93』作為實現邊緣運算的裝置,並介紹一套很重要的開發工具『 vela 工具 』能夠幫助開發者獲得一些模組優化後的數據與程序處理方式。但比較可惜的事情,雖然此工具有提供許多的優化方式,但仍有些功能無法實現於 i.MX93 上。因此仍推薦以 vela 性能(Performance) 作為主要的優化手段 ! 事不宜遲,趕緊使用 i.MX93 打造屬於自己的 AI 裝置吧 !
五、參考文件
[1] i.MX 8 Series Applications Processors Multicore Arm® Cortex® Processors
[2] NXP Document - i.MX Yocto Project User's Guide.pdf
[3] Welcome to the Yocto Project Documentation
[4] NXP Document - i.MX Linux Release Note
[5] NXP Document - i.MX Machine Learning User's Guide
[6] Roboflow
[7] Ultralytics
[8] Arm Ethos-U65
[9] Arm Vela tool
如有任何相關 Machine Learning 技術問題,歡迎至博文底下留言提問 !!
接下來還會分享更多 Machine Learning的技術文章 !!敬請期待 【ATU Book-i.MX系列 - ML】 !!

評論