

前言
高通AIMET [1] 是一個開源程式庫,用於優化已訓練的神經網絡模型。開發者可以將 AIMET 的壓縮和量化算法整合到 PyTorch 和 TensorFlow 的模型構建流程中,用於自動化後訓練優化及模型微調,從而省去手動優化神經網絡的繁瑣過程。而AIMET 的量化模擬 (Quantization Simulation) 提供了模擬量化硬體效果的功能,讓使用者可以在模擬過程中應用後訓練或微調技術,以恢復模型的準確度,最終將模型部署在目標設備上。本篇將介紹量化模擬的基本原理與流程,了解其如何找到模型的最佳量化縮放與偏移參數,以觀察應用這些技術後量化準確度的變化,並以VGG11 [2] 模型為例示範。
QuantSim 工作流程
QuantSim為AIMET之API之一,當 QuantSim 被創建後,可以使用其現有的管道在 QuantSim 物件中微調模型,以下是模擬目標量化精度的工作流程:
- 從預訓練的浮點 FP32 模型開始,並通過在模型圖中插入量化模擬操作來創建模擬模型。
- 找到插入的量化模擬操作的最佳量化參數,如縮放和偏移值,且需要使用者提供回調方法,會將一些具代表性的數據樣本傳遞給模型,以找到最佳量化參數。
- 返回一個量化模擬模型,該模型可以在評估管道中替代原始模型使用。
- 使用者可以調用 .export() 函式保存移除量化節點的模型副本,並生成一個包含每個激活函式和權重張量量化縮放和偏移參數的編碼文件。
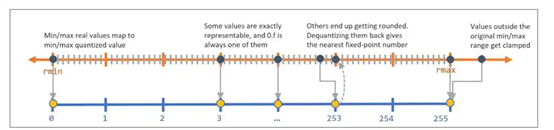
- 導入量化噪聲: 由於反量化後的值可能與量化前的值不完全相同,這兩者之間的差異即為量化噪聲,為了模擬量化噪聲,QuantSim 在模型圖中添加了量化操作節點。生成的模型圖可以直接用於使用者的評估或訓練流程中,圖一顯示如何將實數值(如 rmin 和 rmax)對應到量化值的範圍(如 0 到 255)。
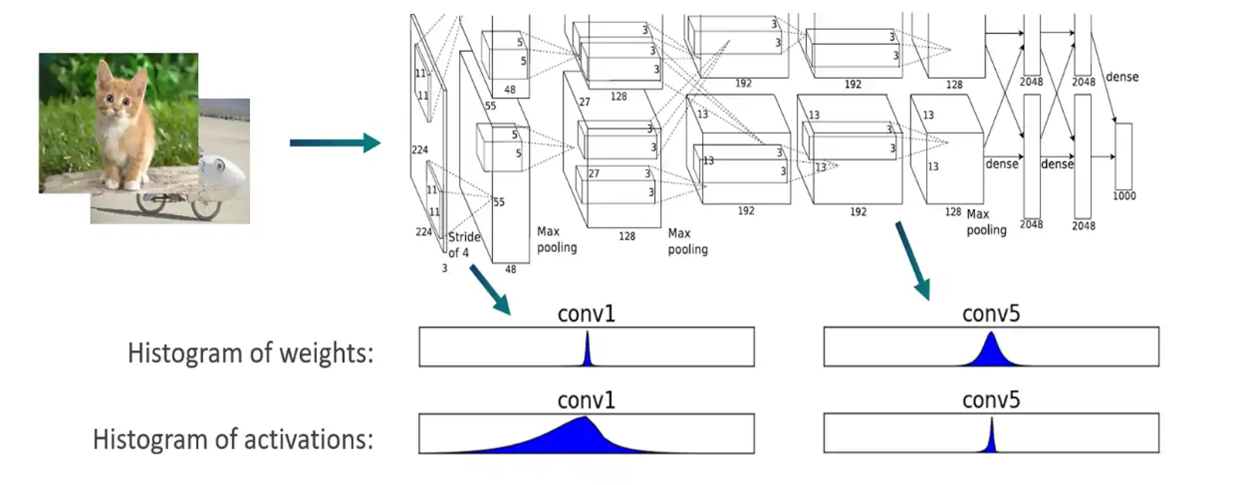
- 確認量化參數: 使用 QuantSim時會分析並確定每個量化操作的最佳量化編碼(即縮放和偏移參數)。會將一些校準樣本通過模型,為每一層的輸出張量創建直方圖來得知浮點數的分佈,如圖二所示,而每層的編碼包括四個數值:Min (qmin)、Max (qmax)、Delta、Offset。
QuantSim以VGG11為例之程式實現
- VGG11介紹: VGGNet 在 2014 年由牛津大學 Visual Geometry Group 提出,特點是重複採用同一組基礎模組,並改用小卷積核替代中大型卷積核,其架構由 n 個 VGG Block 與3個全連接層所組成,如圖三所示。
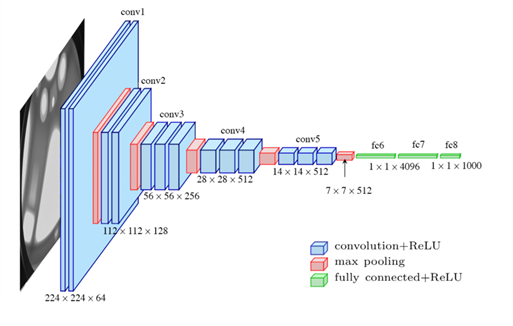 圖三、vgg16 論文上的架構圖。
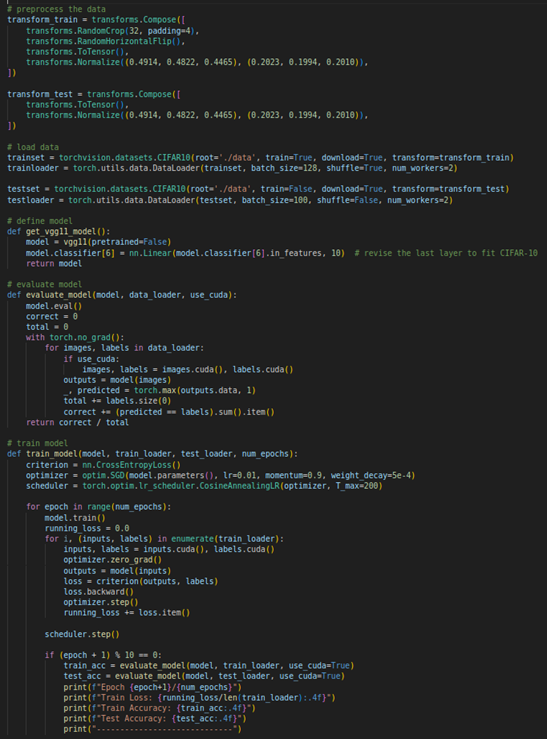
圖三、vgg16 論文上的架構圖。如圖四所示,我們使用PyTorch訓練和評估VGG11模型以進行CIFAR-10圖像分類,首先定義了數據預處理操作和載入CIFAR-10數據集,然後建立了一個適合CIFAR-10的VGG11模型,並使用非預訓練模型進行訓練。
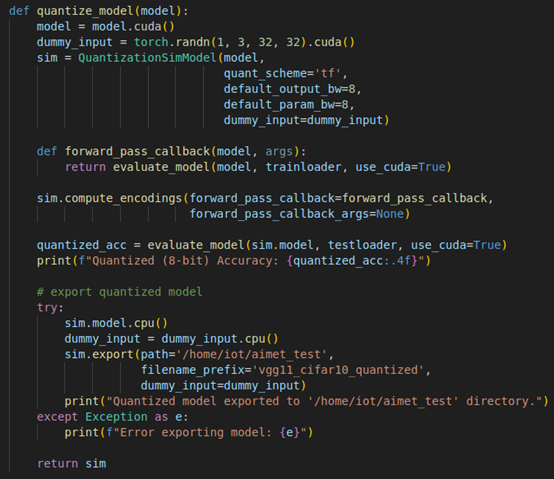
- QuantSim 程式解釋: 如圖五所示,首先,建立一個大小為(1, 3, 32, 32)的隨機張量作為dummy_input,用於模擬輸入資料。然後,使用QuantizationSimModel [3] 建立一個量化模擬模型,設定量化方案為'tf'(TensorFlow風格),且預設輸出和參數均為8bits。接著,定義一個forward_pass_callback函式,用於在計算編碼時評估模型,而 compute_encoding函式則是用來確定最佳的量化參數,隨後,使用測試資料集評估量化後的模型準確率。
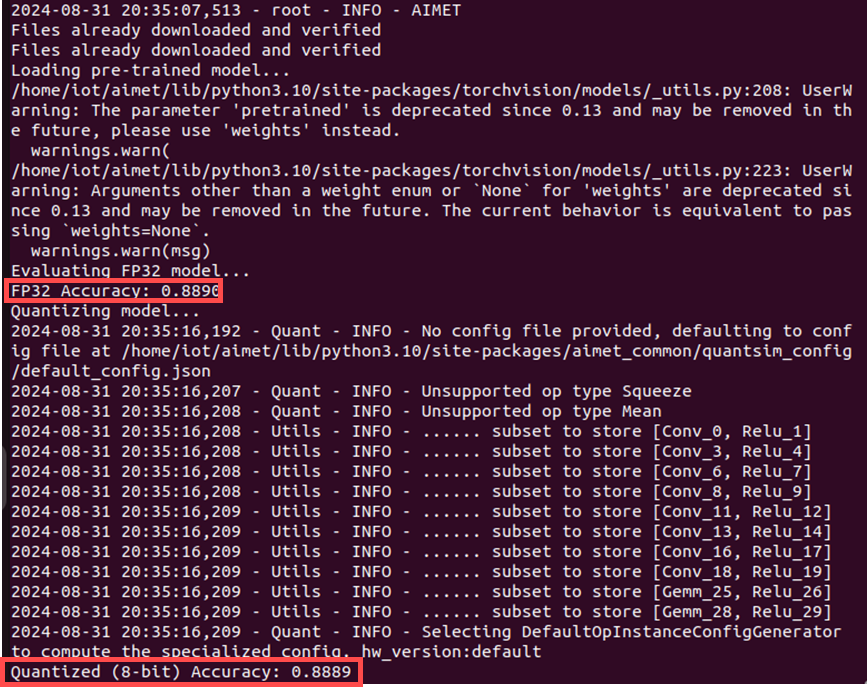
圖六、運行程式後之輸出,可以看到其量化前後之準確率相當。
如圖六所示,可以看到在量化前的準確率為88.90%,而量化後為88.89%,表示量化過程非常成功,幾乎沒有損失準確率。最後,若想保存量化後的模型,可以使用export函式,其除了移除用於模擬量化效果的特殊量化節點,也能將模型轉換為可以直接在標準 PyTorch 環境中運行的格式。
小結
透過以上講解與搭配程式碼進行說明,相信各位對AIMET之量化模擬工具能有更深刻的理解,期待下一篇博文吧!
Q&A
問題一:什麼是模型量化,為什麼在深度學習之部署中如此重要?
模型量化是將深度學習模型的權重和活化值從32位元浮點數轉換為低精度之表示 (如8位元整數) 的過程,其能夠降低運算複雜度、減少記憶體佔用,並提高推理速度,尤其是在嵌入式裝置上。
問題二:AIMET在模型量化過程中扮演什麼角色?
能夠調整,尋找最佳量化參數,並提供量化感知訓練 (Quantization-Aware Training, QAT) 支持,以提高量化模型的精確度,以及產生裝備所需的量化模型和參數檔。
問題三:在AIMET的量化過程中,參數如'quant_scheme'、'default_output_bw'、和'default_param_bw'分別代表什麼?
在 AIMET 的量化過程中,'quant_scheme'是用來指定量化方案,如'tf'表示使用TensorFlow風格的量化。'default_output_bw'設定預設的輸出位元寬,通常為8位元。'default_param_bw'設定預設的參數位寬,同樣通常為8位。
問題四:在實際專案中,如何選擇適當的量化位寬?
許多硬體加速器 (如部分GPU和專用AI晶片) 對8位元硬體損壞有最佳化支援,但對於複雜模型可能需要更高的位寬來保持性能 (如16位元),否則會導致模型能力下降,開發者可以透過實驗找到最佳平衡點。
問題五:模型量化過程中,如何處理和評估模型的穩健性和泛化能力?
除了對資料集增強外,也可以使用量化感知訓練以提高模型的精確度與穩健性,而在AIMET中也有提供此功能的API,且在開發過程中,也要持續監控模型性能並做好驗證。
參考資料
[1] AIMET: https://www.qualcomm.com/developer/software/ai-model-efficiency-toolkit
[2] VGG11: https://arxiv.org/abs/1409.1556
[3] QuantizationSimModel: https://docs.qualcomm.com/bundle/publicresource/topics/80-78122-3/torch_quantsim.html?product=1601111740010414#api-torch-quantsim
評論