

►前言
本篇將講解目前最新推出的YOLOv11搭配Roboflow進行自定義資料標註訓練流程,透過Colab上進行實作說明,使大家能夠容易的了解YOLOv11的使用。
►YOLO框架下載與導入


►Roboflow的資料收集與標註
進行自定義資料集建置與上傳
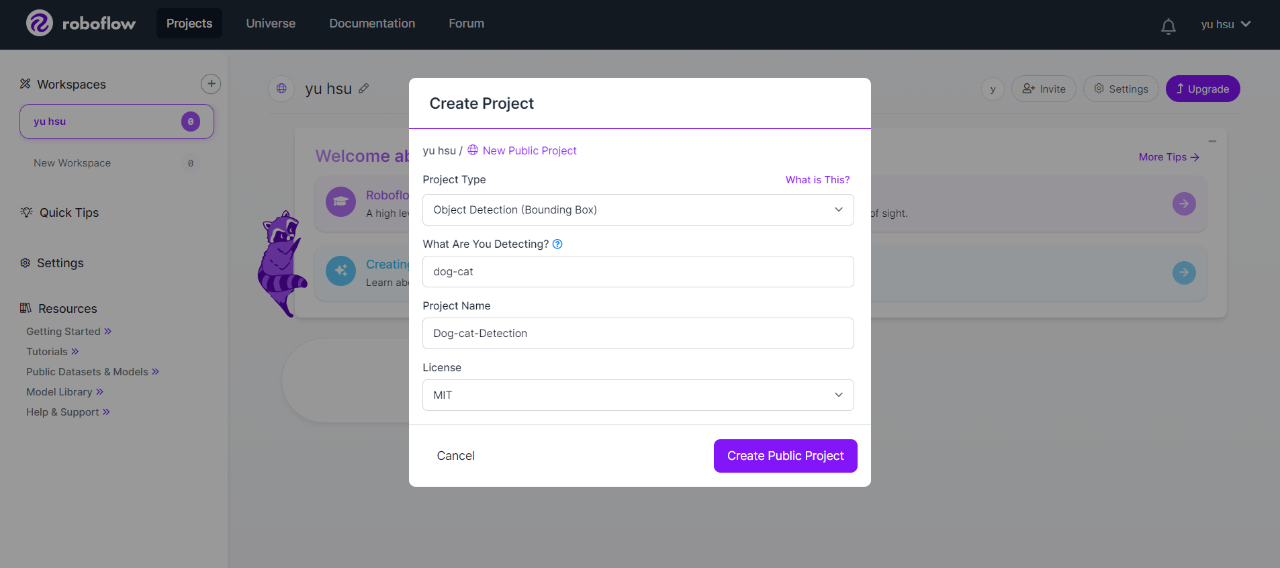
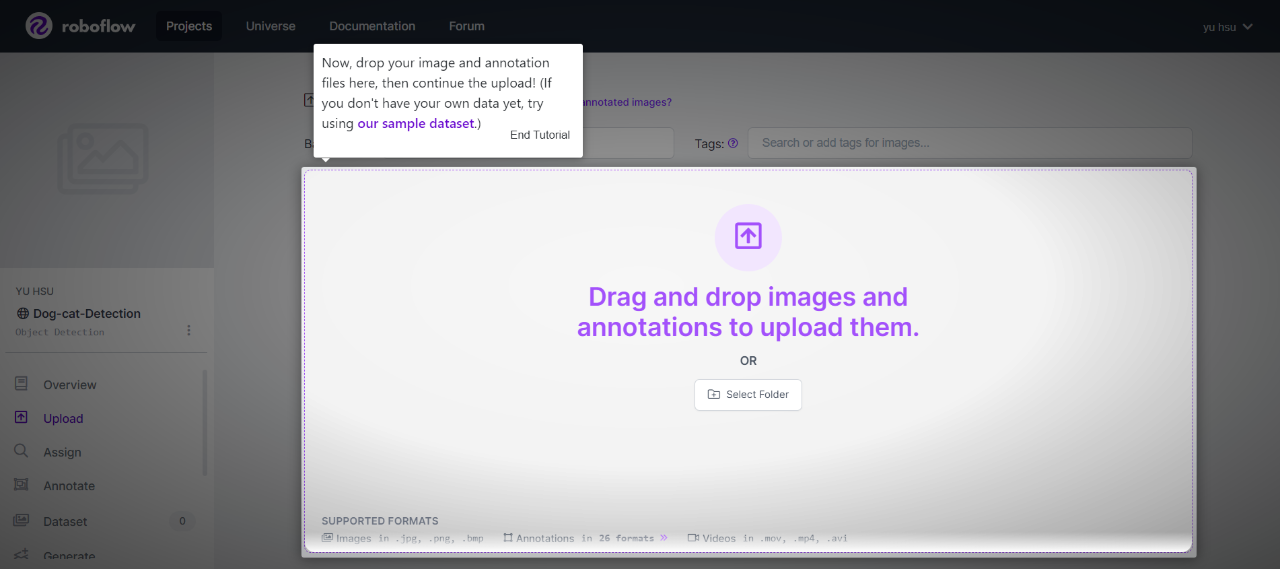
透過Roboflow工具進行資料標註,最後再將訓練資料採用YOLOv11格式輸出。
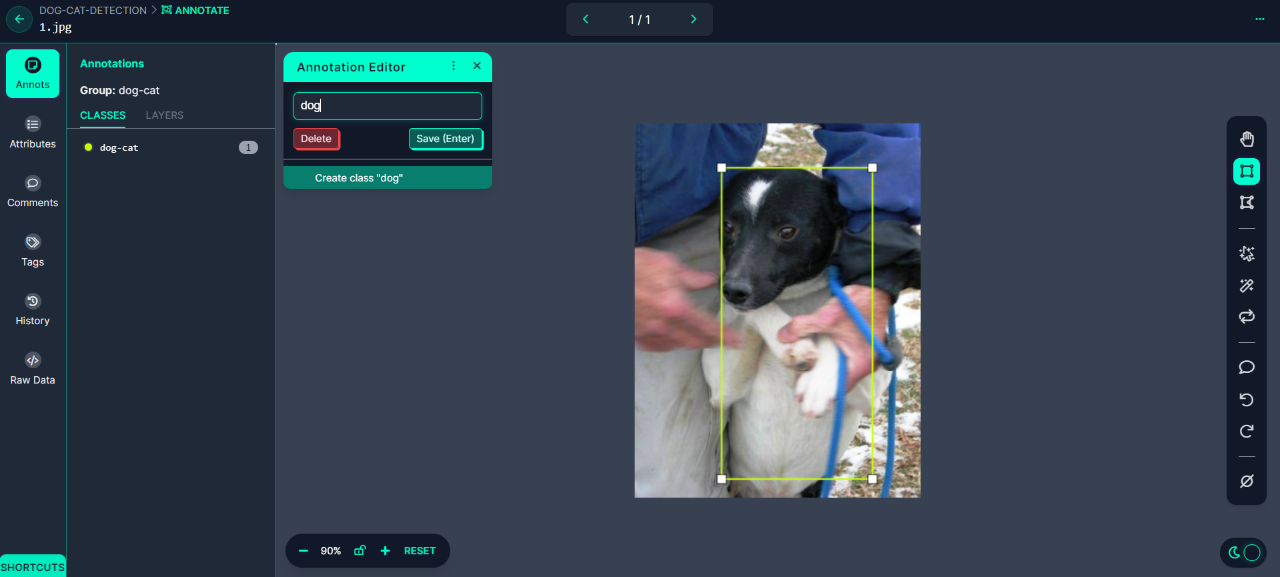
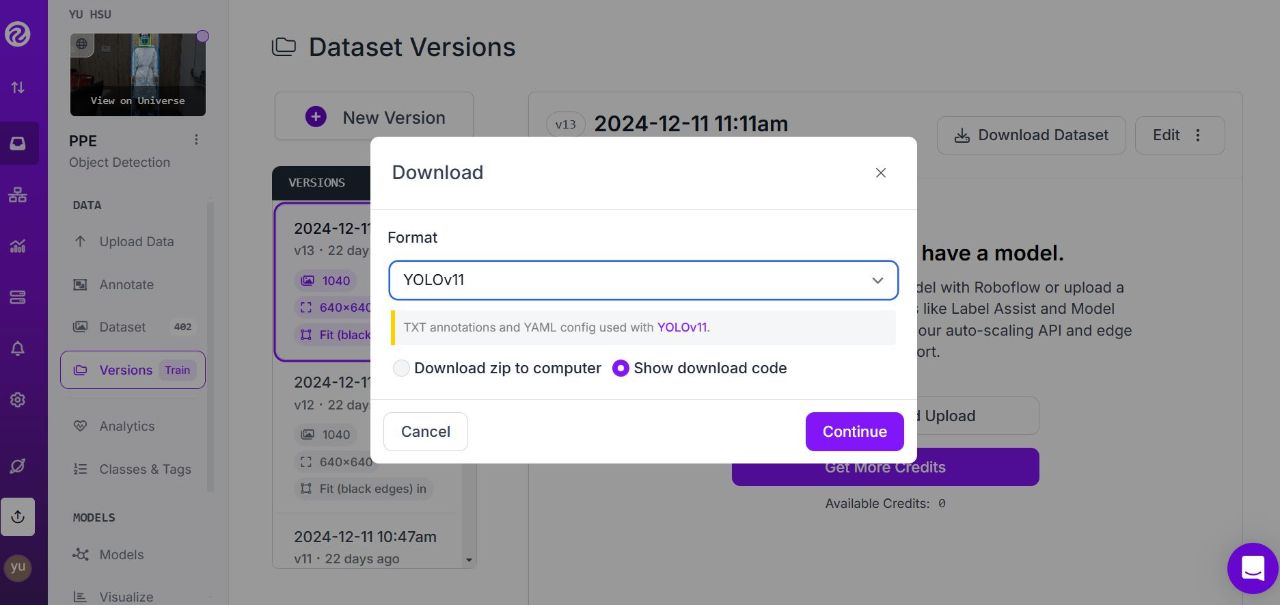
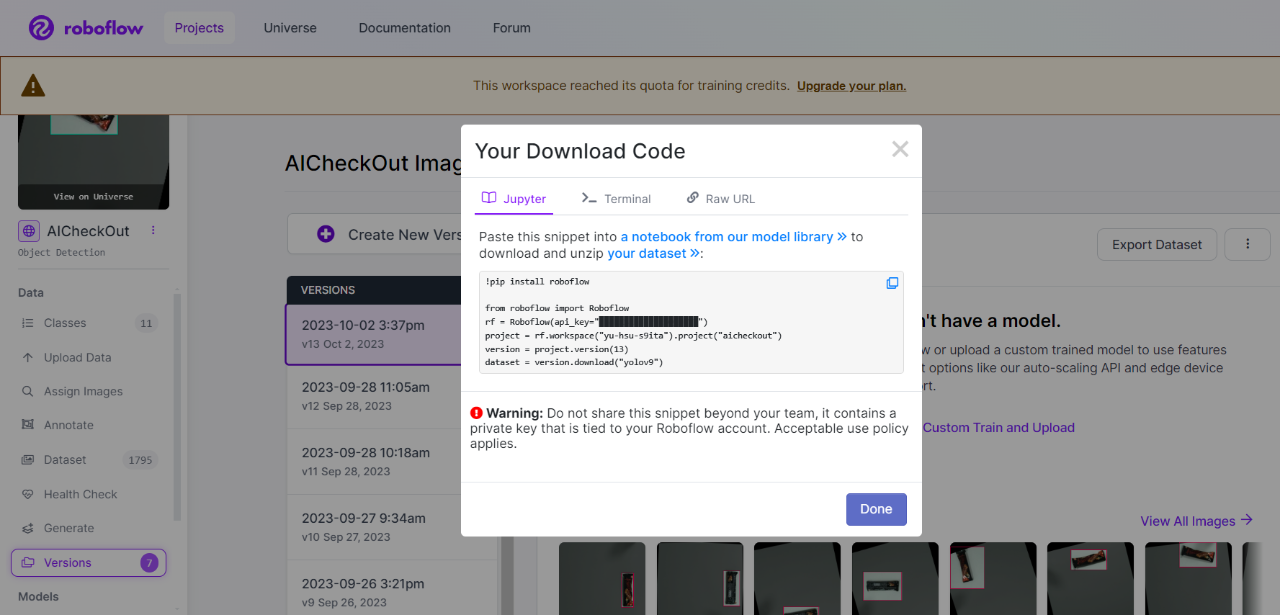
►自定義資料導入
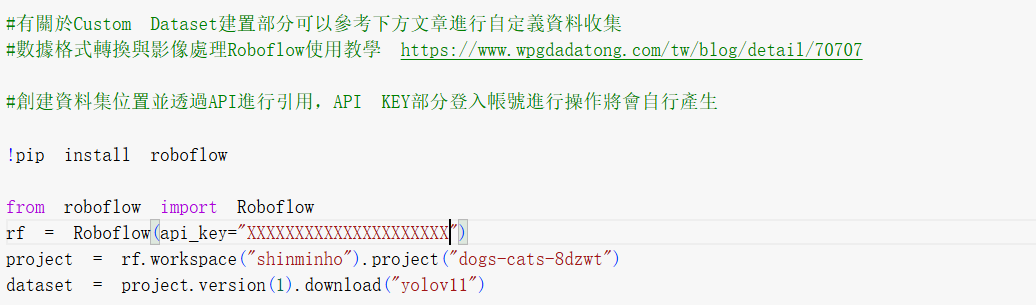
►模型訓練
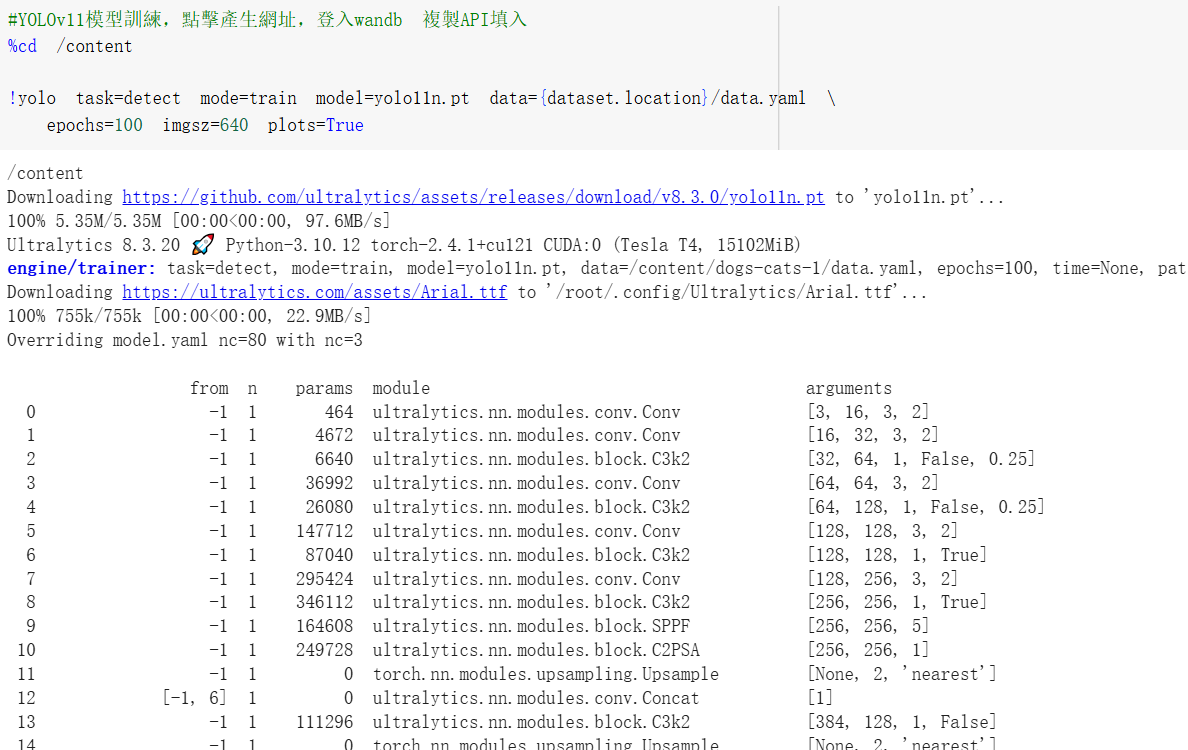
►模型訓練結果可視化
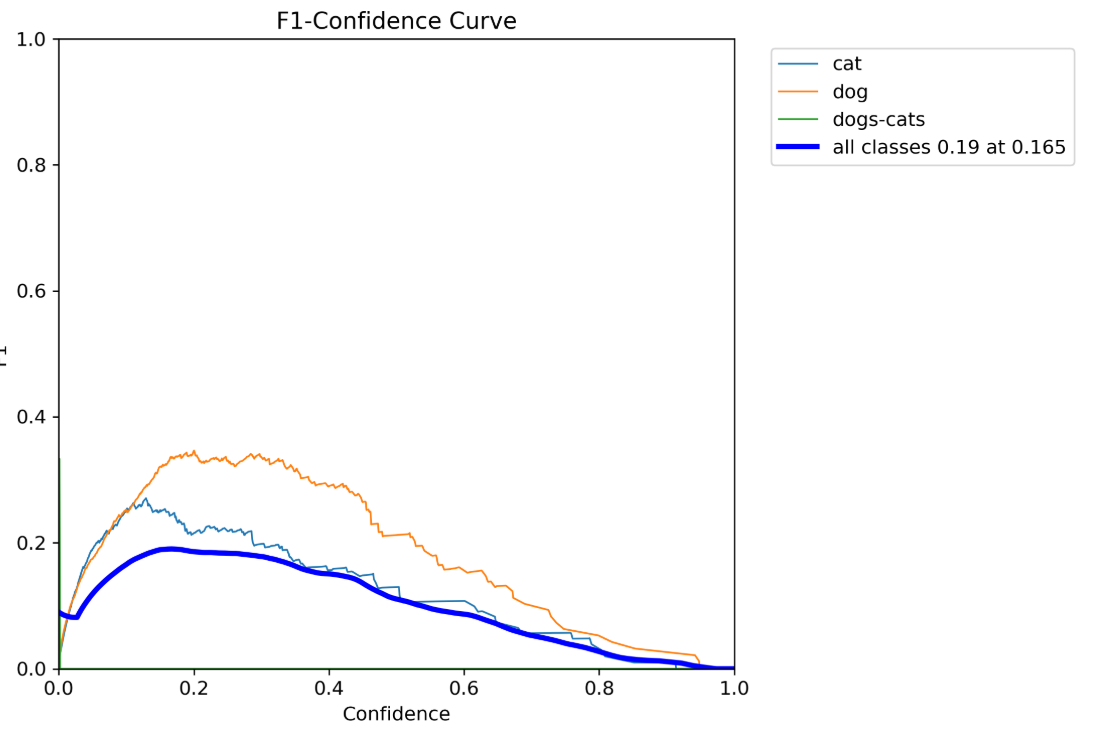
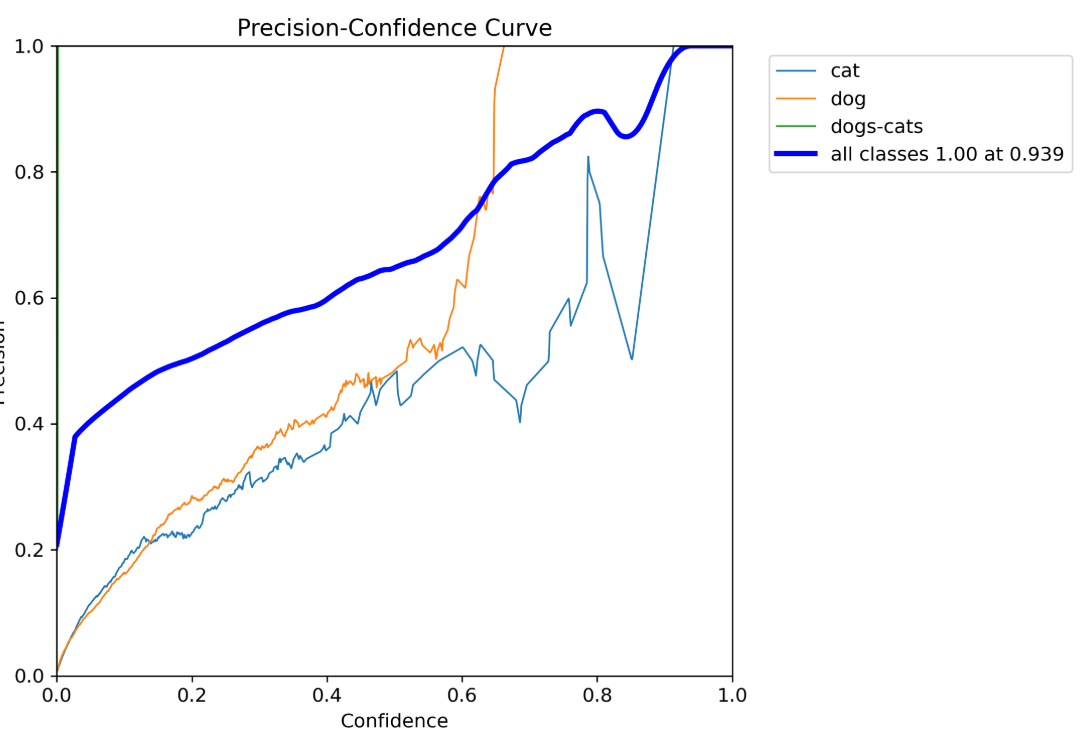
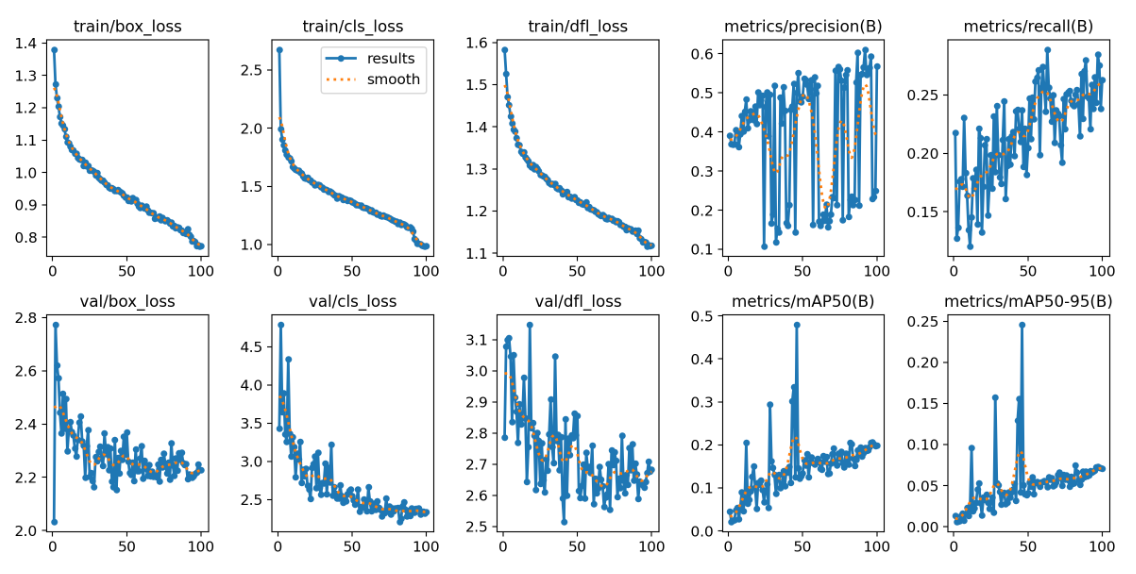
►模型訓練結果可視化
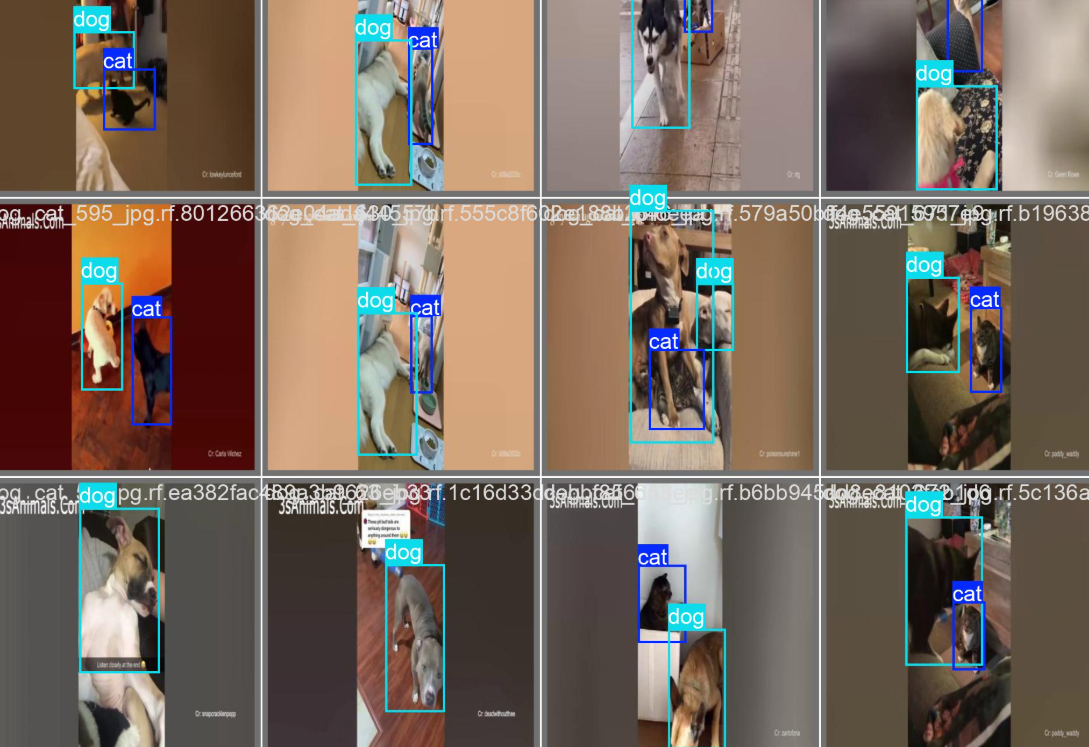
►小結
透過以上講解,在Colab上搭配Roboflow進行自定義資料收集與訓練,能夠更快的進行YOLOv11的模型訓練,可以期待下一篇博文吧!
►Q&A
Q1: YOLOv11 有哪些新特性?:
A1: 透過GPU最佳化和架構改進,YOLOv11的訓練和推理速度比以往版本快得多,延遲減少高達25%。
Q2:YOLOv11包含哪些模型?
A2: 目標檢測模型、實例分割模型、姿態估計模型、旋轉邊界框模型、影像分類模型。
Q3 : YOLOv8 vs YOLOv11:模型效能比較?
A3:YOLOv11n 在精確度上超越了 YOLOv8n,平均精確度(mAP)為 39.5,而 YOLOv8n 為 37.3,顯示 YOLOv11n 在影像中的目標偵測能力更強。
Q4: YOLOv11 是否能夠於嵌入端使用?
A4:目前已能夠透過tensorRT、 NCNN或TFLite,於嵌入端使用。Q5: NCNN與tensorRT差異?
A5: NCNN針對CPU效能進行部署與最佳化,記憶體佔用率低,提供INT8量化支援。TensorRT針對GPU和CPU優化加速模型推理,支援INT8量化和FP16量化。對於嵌入端提供Nvidia GPU可以透過TensorRT進行加速。
評論