

前言
近年來AI人工智能蓬勃發展,各行各業都可以看到使用AI的影子,例如:胸腔科醫生使用AI技術協助醫生判斷X光片是否有肺癌徵兆、工廠使用AOI檢測加上AI技術來達到降低人力成本、無人商店使用AI技術判斷顧客購買的商品項目,等等例子屬不勝數。Caffe MobileNet SSD模型是專門用來進行AI Detection,快速將目標物件框出後再進行其他處理,例如常見的車牌辨識就是先利用Detection方式匡出目標物件,再進行OCR將圖像車牌中的文字題取出來。接下來將介紹Caffe MobileNet SSD模型訓練步驟,從安裝Caffe MobileNet SSD、訓練前處理、訓練模型到最後展示結果一一為各位介紹。
目的
本篇博文將教大家如何從訓練Caffe SSD-Mobilenet 模型到最終辨識車牌。
安裝Caffe
1. 下載caffe,這裡須注意一定要使用下列github網址,因為Caffe SSD-Mobilenet屬於Caffe特殊版本,因此必須git特定版本才有Detection功能。
git clone https://github.com/weiliu89/caffe.git
- 進到caffe路徑,執行git checkout ssd
- 執行cp Makefile.config.example Makefile.config
- 執行sudo apt-get install libhdf5-dev
- 修改Makefile.config檔案
將CPU_ONLY := 1(打開)
將OPENCV_VERSION := 3(打開)
找到INCLUDE_DIRS,在后面添加/usr/include/hdf5/serial
找到LIBRARY_DIRS,在后面添加/usr/lib/x86_64-linux-gnu/hdf5/serial
將PYTHON_LIBRARIES改成PYTHON_LIBRARIES := boost_python3 python3.6m
將PYTHON_INCLUDE改成PYTHON_INCLUDE := /usr/include/python3.6m \
/usr/lib/python3.6/dist-packages/numpy/core/include
- 依序執行以下指令:
make all
make test
make runtest
make distribute
make pycaffe
- 上述步驟完成後即成功安裝SSD版本Caffe。
- 下載MobileNetSSD
Git clone https://github.com/chuanqi305/MobileNet-SSD 至 Caffe/example/中。(圖1)
圖 1
訓練前處理
- 建置訓練Dataset
- 在Caffe/data中建立文件夾放入Annotations(利用labelimg生成對應xml文件)與
JPEGImages(原始文件),這邊須注意使用的是JPG圖檔。(圖2)(關於照片標註可以參考” 如何使用LabelImg”博文)
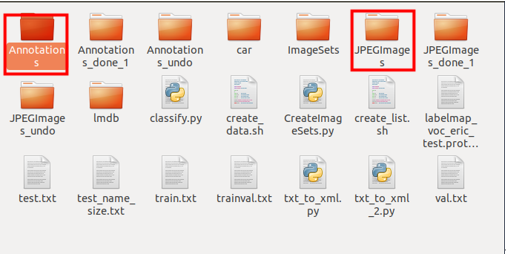
圖 2
-
- 利用以下程式碼生成ImageSet文件夾,此文件夾目錄下包含Main文件下,在ImageSets\Main裡有四個txt文件:test.txt train.txt trainval.txt val.txt;分別是測試數據集索引(也就是各個測試圖片的名稱,相對路徑)、訓練數據集、訓練驗證數據集、驗證數據集。(圖3)
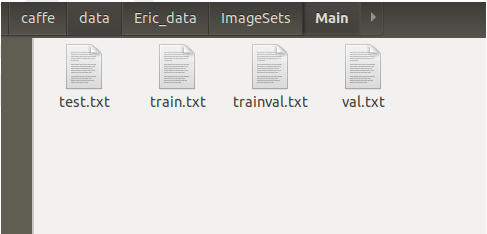
圖 3
Python程式碼:
import os
import random
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
os.makedirs(txtsavepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
-
- 生成lmdb格式文件,在VOC0712文件夾中把以下幾個文件複製到自行建立的資料夾中。(圖4)(圖5)
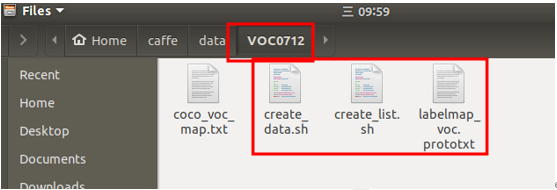
圖 4
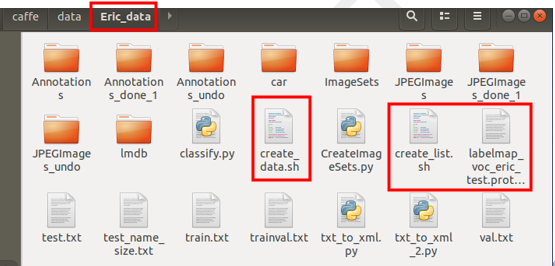
圖 5
-
- 更改create_data.sh內的相關路徑為自建的資料夾名稱。(圖6)
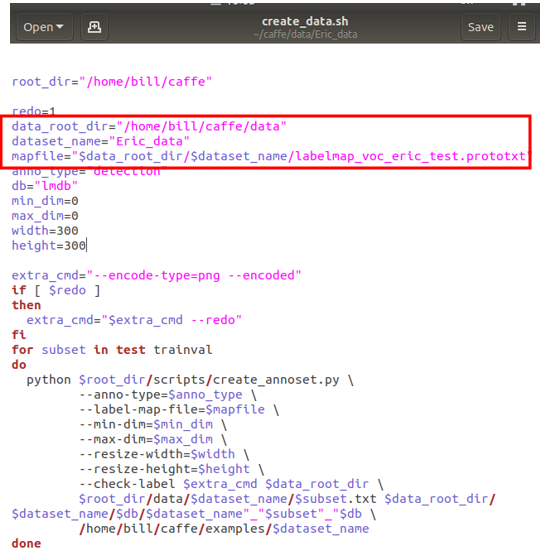
圖 6
- 註解create_list.sh內程式碼,並更改路徑為自建的資料夾。(圖7)
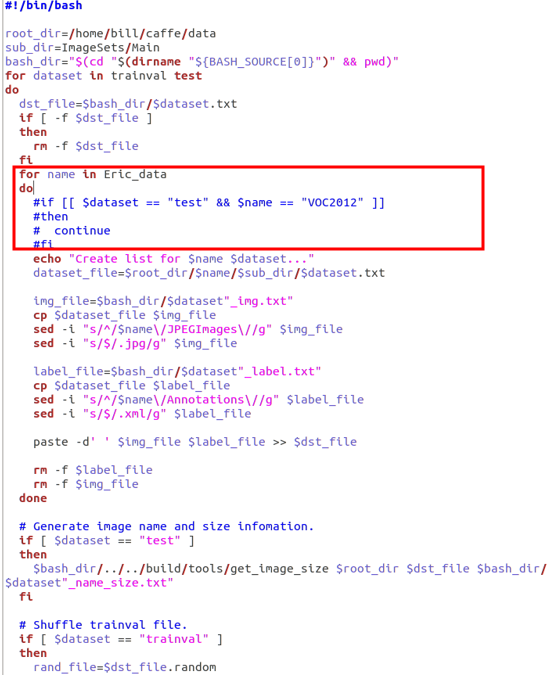
圖 7
- 修改labelmap_voc.prototxt中的label成自建的label。(圖8)
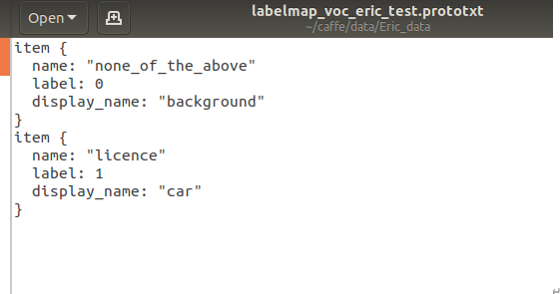
圖 8
- 更改好後依次執行->cd caffe/data/自建dataset資料夾名稱-> create_list.sh->create_data.sh。
- 得到結果如圖9。
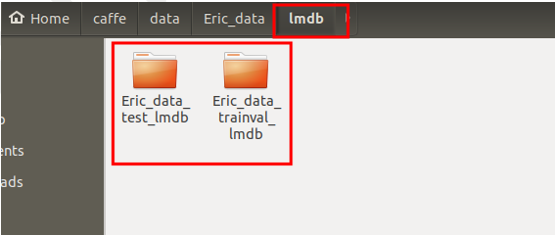
圖 9
- 在caffe/examples中有個與MobileNetSSD平級的目錄MyDataSet,裡面為lmdb文件夾的超鏈接文件,後續訓練使用。(圖10)
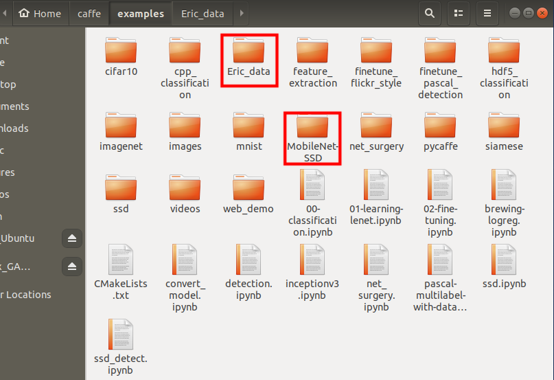
圖 10
結語
“Caffe SSD-Mobilenet 模型訓練流程(ubuntu18.04)-上”主要為各位介紹如何安裝SSD-Mobilenet版本的Caffe,這是非常重要的第一步驟因為接下來訓練模型都是依據在這個版本下執行。下一篇將會為各位介紹如何將標註好的資料集進行Caffe SSD-Mobilenet 模型訓練。(如果不知道如何標注資料集可以參考” 如何使用LabelImg”博文)
評論