

一. 概述
本文主要將介紹恩智浦近期所推廣的 AI 晶片 : 神經處理單元(Neural Process Unit, NPU)。
在本系列的章節中,將會探討關於 NPU 的硬體特性與進階使用的方法,帶領讀者更了解新穎的 AI Chip 的強大之處。若讀者欲快速啟用 NPU 或相關範例的話,請查閱 eIQ 或 PyeIQ 博文 !! 即可透過恩智浦所提供的 ML Framework 快速上手 !! 如下圖文章架構圖所示,此架構圖隸屬於 i.MX8M Plus 的方案博文中,並屬於機器學習內的 硬體層(Hardware Layer) 的 NPU 部分,目前章節介紹 “NPU 架構探討”。
若新讀者欲理解更多人工智慧、機器學習以及深度學習的資訊,可點選查閱下方博文
大大通精彩博文 【ATU Book-i.MX8系列】博文索引
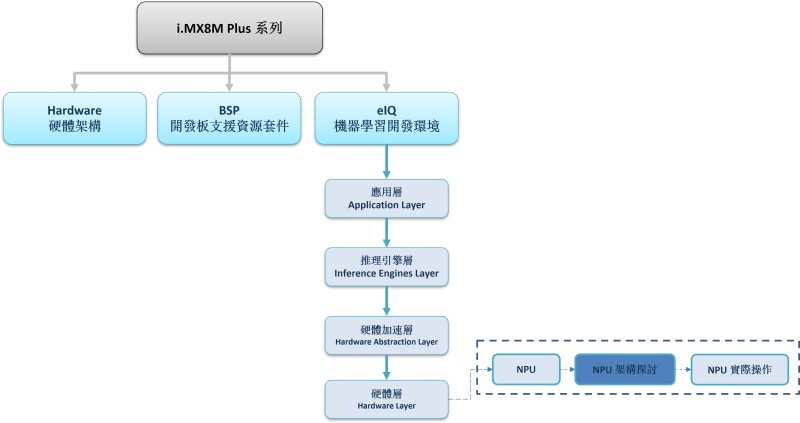
NPU 系列博文-文章架構示意圖
二. NPU 架構概念
在談論 NPU 架構之前,先來探討圖形處理器 GPU 與 神經處理器NPU 兩者架構的差異為何?
所謂的 GPU 是一種擁有大量算術邏輯單元組成的並行計算架構,能夠以多線程的方式來保持高存取速度與浮點數計算能力。但其缺點就是不能單獨運算單一核心,使得功耗相對較高。如下圖所示,在神經網路的應用裡,仍是需要透過 CPU 去解析模組(Model),再將其運算拆分給 GPU完成執行運算。這裡的方式較為直覺,比較像是一層一層去解析作運算,這將花費大量的讀取資料時間 ! 使得 GPU 僅能扮演一個不錯的加速器角色 !
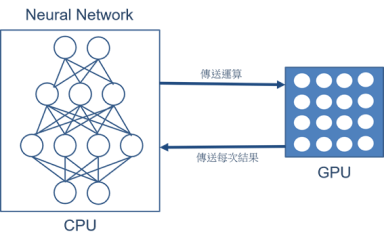
GPU 運算動作之架構示意圖
資料來源 : 每日頭條
另一者,NPU 是一種模擬人類神經元與突觸的新穎架構,能透過一條指令完成一整組的神經元處理。
無須將每層神經元的結果傳送至內存之中,是能夠傳遞給下層記憶運算處理,竟而達到神經網路架構的處理上有著卓越優勢 ! 並大幅度將低耗電等相關問題 !
如下圖所示,不同於 GPU 的方式,這裡 CPU 僅替 NPU 作讀取模組與傳送輸入端的資料,後續就託付給 NPU 進行運算與推理!!
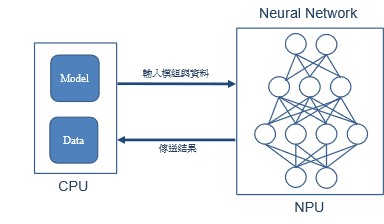
NPU 運算動作之架構示意圖
資料來源 : 每日頭條
以數學演算進行說明
若欲計算 D = A + B + C 的這個算式。則 GPU 僅能 tmp = A + B 後,再進行 D = tmp + C 的動作,這須讀取兩次記憶體資訊才能完成。對於 NPU 而言,僅須一次執行就能完成 D = A + B + C 的算式 !!
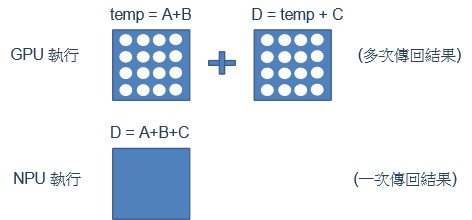
NPU 運算範例示意圖
資料來源 : 每日頭條
然而,在首次進行運算時,NPU 需要花費相當長的時間來建立所謂的神經元或稱推理前的規劃,這裡所花費的時間就稱作 暖開機(WarmUp) !!
此時,就能呼應到所謂的 神經網路處理(Neural Network),如同下方示意圖,而暖開機所耗費的就是在建立神經網路中的參數關係,亦或是建構 神經元(藍色圓圈) 的關係。更直白地想,就是先前替神經網路建立專屬的算式或指令、甚至規劃 !! 當有輸入值時,就能快速演算出結果 !! 這就是 神經網路處理器(NPU) 能快速的原因之一 !!
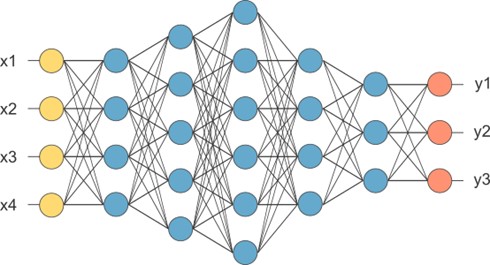
神經網路架構示意圖
三. 架構探討
簡單認識 GPU 與 NPU 的架構差異後,為了讓讀者更清楚 NPU 的內部架構,緊接著就要介紹 NPU 的細部架構與硬體加速層的探討。
細部架構探討
如下圖所示,為 神經處理器 NPU(Neural Processing Unit) 細節架構 :
(1) 主接面(Host Interface) :
為 AXI / AHB 接面、視覺前端程序(Vision Front End and Scheduler) 與 記憶體控制器(Memory Controller) 的通訊橋樑。
(2) 視覺前端程序(Vision Front End and Scheduler) :
是將命令傳送至 神經處理模組(NPU Modules) 與 存儲緩存單元(Universal Storage Cache) 的一套程序或是排程(pipeline)。
(3) 神經處理單元模塊(Neural Processing Unit Modules) :
為推理應用的主要單元,是由 程序化引擎單元(Programmable Engine Unit) 與 神經網路引擎(Neural Network Engine) 兩塊模組構成
(4) 存儲緩存單元(Universal Storage Cache) :
NPU Modules 與 Vision Front End 共享緩衝單元。
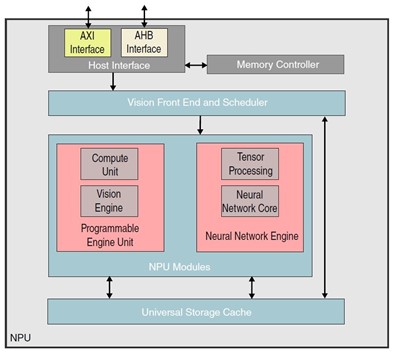
NPU 架構示意圖
資料來源 : 官方網站
其中,神經處理模塊(NPU Modules) 可拆分出 :
(1) 程序化引擎單元(Programmable Engine Unit)
計算單元(Compute Unit) : 為 SIMD 架構的小型處理器。
視覺引擎(Vision Engine) : 提供高級圖像處理之功能。
(2) 神經網路引擎(Neural Network Engine)
張量處理(Tensor Processing) : 提供資料預處理、支援壓縮和剪修與多維度的張量數組處理。
神經網路核心(Neural Network Core) : 提供整數之卷積或矩陣運算功能。
神經網路引擎(Neural Network Engine) 細部規格 :
主要應用方向為分類(Classification)、偵測(Detection)、分割(Segmentation),且能夠運行 LeNet, AlexNet, VGG, GoogleLeNet 等神經網路模組架構、以及支持 RNN 遞歸神經網路。同時,作為 OpenVX 與 TensorFlow backend 推理引擎的基底,即可運行 TensorFlow Lite / ONNX / ArmNN / Caffe 等深度學習框架所訓練出的模組…
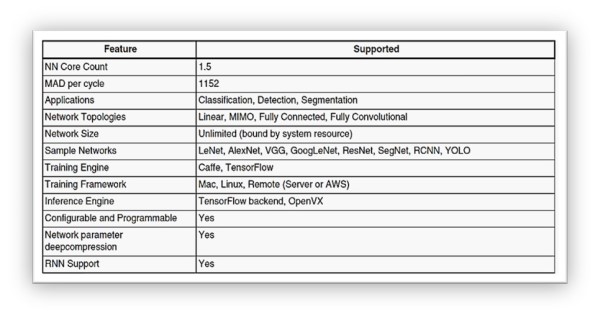
神經網路引擎細部規格
資料來源 : 官方網站
張量處理單元(Tensor Processing) 細部規格 :
能以 8 與 16 位元的整數進行張量運算處理,並支持最大與平均池化層、 ReLU 與 Leaky ReLU 激活層、正歸化等神經網路架構層…
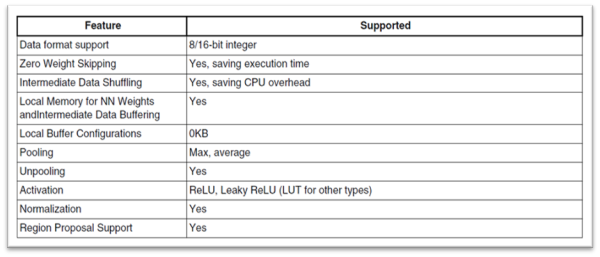
張量處理單元細部規格
資料來源 : 官方網站
除了上述架構之外,還有一個重要的 平行處理單元(Parallel Processing Unit) 架構,主要負責以平行化計算的方式來處理浮點數或半浮點數的一些運算,以及一些部分無法量化為全整數的操作層(Operator) 將由此層進行運算 !! 若欲得知各層所負責推理的單元處理器為何,請至附錄查看。
平行處理單元(Parallel Processing Unit, PPU) 細部規格 :
以 單指令流多資料流(SIMD) 的方式進行操作,每次最大指令數量為 1M 個與最大 8 條資料串流進行傳送,並支援及閘(AND)、或閘(OR)、是否為空值(ISNAN) 等計算方式…
PS : 在 Profiling Log 中,平行處理單元(PPU) 等同於 Shader(SH)
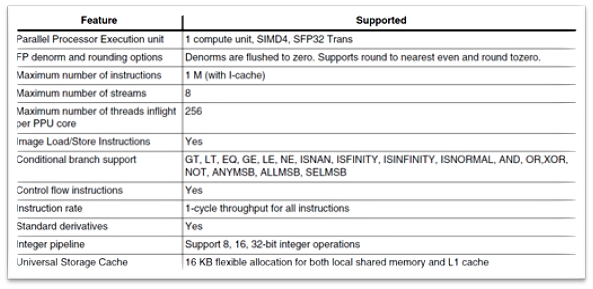
平行處理單元細部規格
資料來源 : 官方網站
硬體加速層探討
然而,在 NXP i.MX8 系列的推理引擎架構中,不論是使用 TensorFlow Lite、ONNX 、 ArmNN 皆會透過 OVXLib 驅動 OpenVX Driver 來啟動 NPU 神經網路處理器 !!
所謂 OpenVX 架構是一種介於軟體層與硬體層之間的架構層,或是資料庫(Lib)。換句話說,就是負責向硬體加速器或是運算器溝通的軟體架構層,透過供應商所提供的指令集而達到運算效能最佳化之目的。比起熟知 OpenCL 資料庫,OpenVX 所提供資源更為廣闊,適用的硬體資源更不侷限於圖形處理器 GPU 、且支持多種硬體加速器,包括其數位信號處理器 DSP、視覺處理單元 VPU、神經網路處理器 NPU 等等 !! 可說是近年相當成熟的硬體加速資料庫 !
PS : OpenVX 與 OpenCL 相同皆是以 C 語言作為主要編譯語言
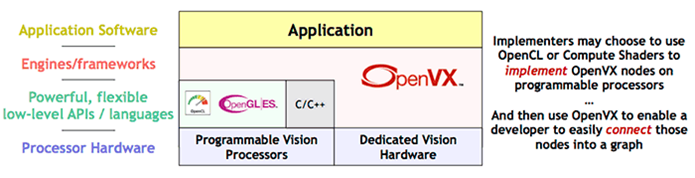
OpenVX 軟體架構示意圖
資料來源 : 官方網站
從 NXP i.MX8 的機器學習軟體架構探討。如下圖紅框所示, NXP 提供了數種硬體加速層的支援,如同 OpenVX、OpenCL 以及 Arm Compute Library 硬體加速資料庫,給予使用者更有效更快速的應用方式 !! 這裡可惜的事,目前官方尚未明確演示 NPU 與 OpenVX 之間的用法,細節仍待進一步鑽研 !! 而一般讀者或開發者僅須要透過使用上一層的 TensorFlow Lite、ONNX、 ArmNN 等開源推理引擎(Open Source Inference Engines) 來完成推理即可 !!
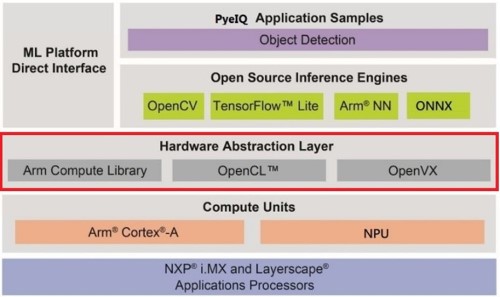
i.MX8 機器學習軟體架構示意圖
資料來源 : 官方網站
目前版本 : OpenVX 1.2
OpenVX 硬體加速相關範疇 :
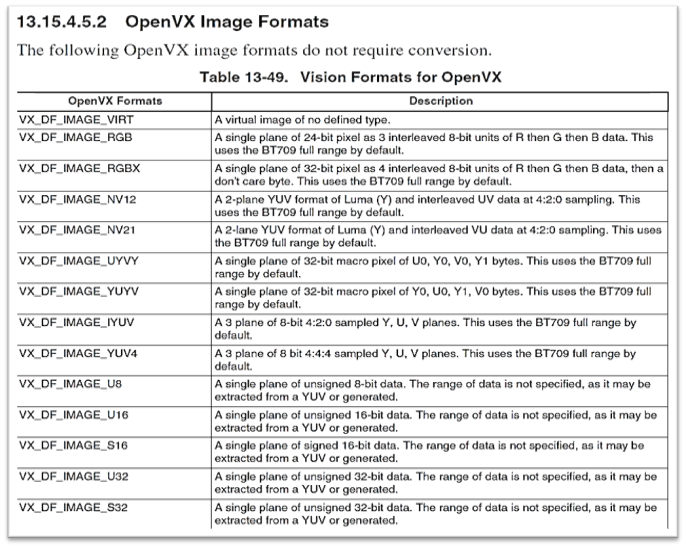
硬體加速資料庫 OpenVX 可以提供 NPU 載入圖像時的硬體支援,並給予一些基本的影像處理資源。
如下表所示,有一系列的 3x3 濾波器、直方圖、位元操作等等模塊,最大遮罩大小能夠為 11x11 以及 8 / 16 位元的點積運算…

OpenVX 硬體加速相關範疇 :
四. 結語
本文已向讀者闡明 GPU 與 NPU 的差異以及 NPU 的細部結構一些基本概念的介紹,並說明 OpenVX 在整個推理流程上的重要性,以及 i.MX8 機器學習軟體架構圖等等。而本篇除了傳遞 NPU 相關的細節資訊外,最重要的事,就是想傳達一個概念 ; “恩智浦提供了完善的開發環境,開發者僅須要專注於模組開發與機器學習框架的使用,即可快速上手 !!“ 。 此系列後續還會向讀者介紹一些關於 NPU 暖開機、資訊顯示等等方法 !! 敬請期待 !!
五. 參考文件
[1] 官方文件 - i.MX Machine Learning User's Guide
[2] 官方文件 - ISP and NPU
[3] 官方文件 - i.MX 8M Plus NPU Warmup Time
如有任何相關 NPU 技術問題,歡迎至博文底下留言提問 !!
接下來還會分享更多 NPU 的技術文章 !!敬請期待 【ATU Book-i.MX8 系列 - NPU】 !!

評論