

一. 概述
在邊緣運算的重點技術之中,模組輕量化網路架構 是不可或缺的一環,如何高效的利用硬體資源來達到最佳目標,特別是在效能與準確度的衡量上,是個非常有趣的議題。此章節再來探討深度學習熱門的研究項目之一 表情識別(Facial Emotion Recognition) ,主要用於偵測人的面部表情,像是生氣(angry)、厭惡(disgust)、恐懼(fear)、快樂(happy)、悲傷(sad)、驚喜(surprise), 自然(neutral) 等等,亦稱 臉部表情識別(Facial Expression Recognition)。其作法通常須搭配人臉偵測來檢測出人臉後,方能進行表情識別的偵測。本章節將以最基本的 卷積神經網路架構 CNN ( Convolutional Neural Network) 與 Kaggle 提供的 臉部表情(Facial Expressio) 資料來進行實現。
若新讀者欲理解更多人工智慧、機器學習以及深度學習的資訊,可點選查閱下方博文
大大通精彩博文 【ATU Book-i.MX8系列】博文索引
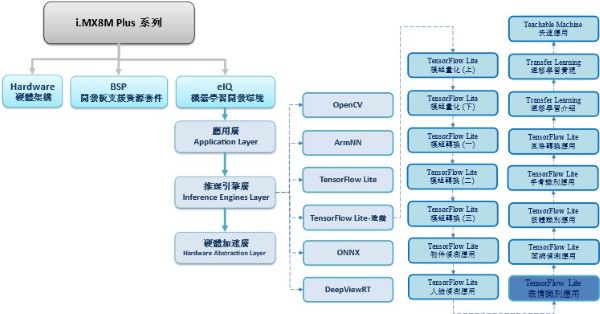
TensorFlow Lite 進階系列博文-文章架構示意圖
二. 算法介紹
神經網路架構探討 : Convolutional Neural Network
為深度學習最基礎的網路架構,如下圖所示。輸入影像資料後,接著 卷積層(Convolution Layer) 以逐步掃描去提取特徵,並搭配 池化層(Pooling Layer) 去縮減資料量作次取樣 Subsampling。
這兩個架構層將會不斷提取影像中的特徵,即貫徹 深度(Deep) 的概念。因此要設計多少架構層,提取多少特徵都是設計者可以自行決定的。
同樣的,架構的深淺也直接影響到辨識率的好壞!! 在架構的最後,將利用 全連階層(Fully Connected Layer) 去串聯所有神經元來達到分類預測之目的。
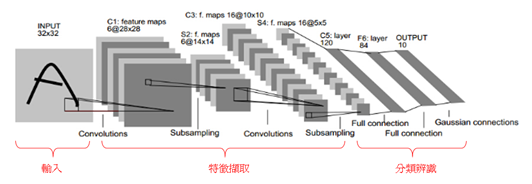
CNN 架構示意圖, 圖文出處- GGWithRabitLIFE 網誌

CNN 各架構層作用之示意圖, 圖文出處- AI 知識庫
三. 算法實現
這裡仿照 Kaggle 的設計來完成一套簡易的表情識別(Facial Emotion Recognition)。
範例連結 : https://www.kaggle.com/shawon10/facial-expression-detection-cnn/log?select=fer2013.csv
實現步驟如下:
第一步 : 開啟 Colab 設定環境
%tensorflow_version 2.x第二步 : 連接 Google Drive 下載資料庫
此步驟已先將所須資料庫存放於 Google 雲端中,請於點選連結下載。
# 連接至 google drive
from google.colab import drive
drive.mount('/content/drive')
# 新增資料夾
%cd /root
!mkdir datasets
# 下載並解壓縮人臉表情資料庫
%cd datasets
!unzip "/content/drive/MyDrive/Colab DataSet/Facial Expression Recognition/Facial Expression Recognition.zip"第三步 : 載入資料庫
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 載入資料,並存放於DataFrame資料型態中
filname = '/root/datasets/fer2013/fer2013/fer2013.csv' # 如下圖所示
label_map = ['Anger', 'Disgust', 'Fear', 'Happy', 'Sad', 'Surprise', 'Neutral']
names=['emotion','pixels','usage']
df=pd.read_csv(filname,names=names, na_filter=False)
im=df['pixels']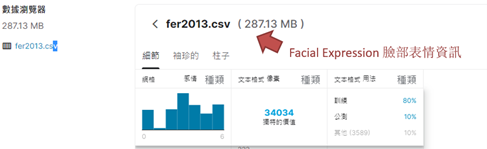
第四步 : 數據特徵整理
此步驟是將所載入的資料,拆分處理成訓練與測試資料、訓練與測試標籤。
def getData(filname):
Y = []
X = []
first = True
for line in open(filname):
if first:
first = False
else:
row = line.split(',')
Y.append(int(row[0]))
X.append([int(p) for p in row[1].split()])
X, Y = np.array(X) / 255.0, np.array(Y)
return X, Y
# 將資料切分成 訓練 與 測試
from sklearn.model_selection import train_test_split
X, Y = getData(filname)
X = X.reshape(X.shape[0], 48, 48, 1)
num_class = len(set(Y))
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.1, random_state=0)
y_train = (np.arange(num_class) == y_train[:, None]).astype(np.float32)
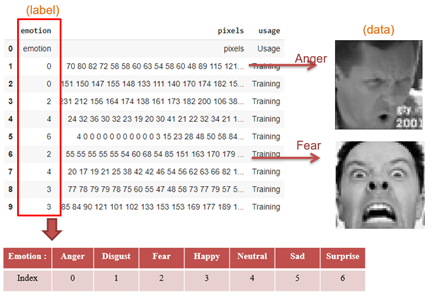
y_test = (np.arange(num_class) == y_test[:, None]).astype(np.float32)如下圖所示,將 fer2013.csv 內的數據作整理。Emotion 為訓練/測試標籤、Pixel 為訓練/測試資料。
第五步 : 建立神經網路
import tensorflow as tf
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D
from keras.layers import Dense, Activation, Dropout, Flatten
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.layers.normalization import BatchNormalization
from keras.callbacks import ModelCheckpoint
# 建立模組架構
model = Sequential()
input_shape = (48,48,1)
model.add(Conv2D(64, (5, 5), input_shape=input_shape,activation='relu', padding='same')) # 卷積層
model.add(Conv2D(64, (5, 5), activation='relu', padding='same')) ## 卷積層
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2))) # 最大池化層
model.add(Conv2D(128, (5, 5),activation='relu',padding='same')) # 卷積層
model.add(Conv2D(128, (5, 5),activation='relu',padding='same')) # 卷積層
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2))) # 最大池化層
model.add(Conv2D(256, (3, 3),activation='relu',padding='same')) # 卷積層
model.add(Conv2D(256, (3, 3),activation='relu',padding='same')) # 卷積層
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2))) # 最大池化層
model.add(Flatten())
model.add(Dense(128)) # 全連接層
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(7)) # 全連接層
model.add(Activation('softmax'))
# 最佳化參數與損失函式設定 -> 這裡取用 'categorical_crossentropy' 作為損失函示、採用 Adam 的最佳化方法
model.compile(loss='categorical_crossentropy', metrics=['accuracy'],optimizer='adam')
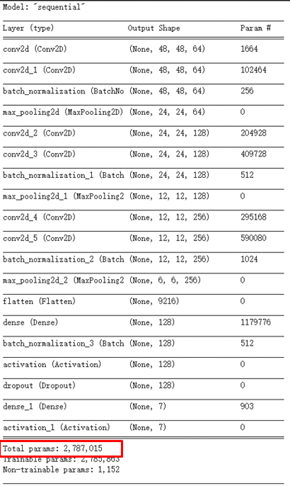
model.summary()所建置的模組架構組成如下,共產生 2,787,015 個參數。(因目前階層少,故參數量不算多)
第六步 : 進行訓練
history = model.fit(X_train_new, y_train, epochs=50, batch_size=64, validation_split=0.2)
model.save("/root/facial_expression_detection.h5") # 訓練完成後, 儲存模組第七步 : TensorFlow Lite 轉換
import tensorflow as tf
import numpy as np
def representative_dataset_gen():
for _ in range(250):
yield [np.random.uniform(0.0, 1.0, size=(1, 48, 48, 1)).astype(np.float32)] converter = tf.compat.v1.lite.TFLiteConverter.from_keras_model_file('/root/facial_expression_detection.h5')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.float32
converter.representative_dataset = representative_dataset_gen
tflite_model = converter.convert()
with open('/root/facial_expression_detection.tflite','wb') as f:
f.write(tflite_model)
print("tranfer done!!")
※ 訓練完成後,將於 /root 資料夾內產出 facial_expression_detection.tflite 檔案
第八步 : Facial Emotion Recognition 範例實現 (於 i.MX8M Plus 撰寫運行)
這裡需搭配人臉偵測找出人臉位置,若相關模型請查看 ”人臉偵測(Face Detection) ” 章節
import cv2
import numpy as np
from tflite_runtime.interpreter import Interpreter
# 載入人臉檢測器(face detector) , 解析 tensorflow lite 檔案
interpreterFaceExtractor = Interpreter(model_path='mobilenetssd_uint8_face.tflite')
interpreterFaceExtractor.allocate_tensors()
input_details = interpreterFaceExtractor.get_input_details()
output_details = interpreterFaceExtractor.get_output_details()
width = input_details[0]['shape'][2]
height = input_details[0]['shape'][1]
# 載入人臉表情檢測器(Facial Emotion Recognition) , 解析 tensorflow lite 檔案
emotion_dict = {0: "Angry", 1: "Disgusted", 2: "Fear", 3: "Happy", 4: "Neutral", 5: "Sad", 6: "Surprised"}
interpreterFacailEmotion = Interpreter(model_path='facial_expression_detection.tflite') # 記得將模組移動至 i.MX8 平台
interpreterFacailEmotion.allocate_tensors()
input_facial_details = interpreterFacailEmotion.get_input_details()
output_facial_details = interpreterFacailEmotion.get_output_details()
facial_input_width = input_facial_details[0]['shape'][2]
facial_inpu_height = input_facial_details[0]['shape'][1]
facial_output_num = output_facial_details[0]['shape'][1]
# 載入測試影像
frame = cv2.imread('yichan.jpg')
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_resized = cv2.resize(frame_rgb, (width, height))
input_data = np.expand_dims(frame_resized, axis=0)
# 檢測出人臉
interpreterFaceExtractor.set_tensor(input_details[0]['index'], input_data)
interpreterFaceExtractor.invoke()
# 人臉位置資訊
detection_boxes = interpreterFaceExtractor.get_tensor(output_details[0]['index'])
detection_classes = interpreterFaceExtractor.get_tensor(output_details[1]['index'])
detection_scores = interpreterFaceExtractor.get_tensor(output_details[2]['index'])
num_boxes = interpreterFaceExtractor.get_tensor(output_details[3]['index'])
# 檢索每張人臉特徵
for i in range(1):
if detection_scores[0, i] > .5: # 預測值大於 0.5則顯示
x = detection_boxes[0, i, [1, 3]] * frame_rgb.shape[1]
y = detection_boxes[0, i, [0, 2]] * frame_rgb.shape[0]
cv2.rectangle(frame, (x[0], y[0]), (x[1], y[1]), (0, 255, 0), 2) # 框出人臉位置
# 擷取人臉,並重新調整大小
roi_x0 = max(0, np.floor(x[0] + 0.5).astype('int32'))
roi_y0 = max(0, np.floor(y[0] + 0.5).astype('int32'))
roi_x1 = min(frame.shape[1], np.floor(x[1] + 0.5).astype('int32'))
roi_y1 = min(frame.shape[0], np.floor(y[1] + 0.5).astype('int32'))
# 感興趣區域
roi = frame_rgb[ roi_y0 : roi_y1, roi_x0 : roi_x1, : ]
# 轉灰階影像
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
roi_resized = cv2.resize(roi, (facial_input_width, facial_inpu_height))
input_facial_data = np.expand_dims(roi_resized, axis=0)
input_facial_data = np.expand_dims(input_facial_data, axis=3) # 調整表情檢測器之輸入張量
# 檢測出人臉表情
interpreterFacailEmotion.set_tensor(input_facial_details[0]['index'], input_facial_data)
interpreterFacailEmotion.invoke() # 進行推理
# 標記文字(表情)
text_x = roi_x0
text_y = min(np.floor( roi_y0 - 10 + 0.5 ).astype('int32'), frame.shape[0])
emotion = interpreterFacailEmotion.get_tensor(output_facial_details[0]['index']) # 輸出各別類別的機率
cv2.putText(frame, emotion_dict[np.argmax(emotion)],\
( text_x, text_y ), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 0, 255), 3, cv2.LINE_AA)
cv2.imshow('Emotion', frame)
cv2.waitKey(0)
cv2.destroyAllWindows()Facial Emotion Recognition 實現結果呈現
如下圖所示,成功檢測出臉部表情。
在 i.MX8M Plus 的 NPU 處理器,推理時間(Inference Time) 約 3 ms。


※ 該模型準確度僅有 7 成,且易受到人臉偵測所給予的輸入資訊。故效果有限,仍須改良。
四. 結語
臉部表情識別(Facial Expression Recognition) 是一套人臉偵測的延伸應用,適用於人臉偵測後,再次偵測該項目。目前運行在 i.MX8MP 的 Vivante VIP8000 NPU,其推理時間可達每秒 3 ms 的處理速度,約 330 張 FPS 。而此範例是以最基礎的 CNN 模組架構 與 Kaggle 的資料庫來建置此應用,因此蠻推崇初學者可以常去 Kaggle 開發各式各樣的 AI 應用。下一章節將會介紹人臉偵測的延伸應用之一的 面網偵測(Face Mesh) !! 敬請期待 !!
五. 參考文件
[1] SSD: Single Shot MultiBox Detector
[2] SSD-Tensorflow
[3] Single Shot MultiBox Detector (SSD) 論文閱讀
[4] ssd-mobilenet v1 演算法結構及程式碼介紹
[5] Get models for TensorFlow Lite
[6] widerface-to-tfrecord
[7] FACIAL EXPRESSION RECOGNITION IN THE WILD USING RICH DEEP FEATURES
[8] ImageNet Classification with Deep Convolutional Neural Networks
[9] Facial Expression Database
[10] Convolution Neural Network 卷積神經網路
[11] 卷积神经网络 – CNN
[12] Facial Expression Detection (CNN)
如有任何相關 TensorFlow Lite 進階技術問題,歡迎至博文底下留言提問 !!
接下來還會分享更多 TensorFlow Lite 進階文章 !!敬請期待 【ATU Book-i.MX8系列 – TFLite 進階】 !!
評論